Lang. Identification in Code Mixed Text - Lit. Review 3
I am reviewing the literature available on language identification for multilingual documents, focusing on Indic languages. I’ll try to cover it in chronological order, but there might be a few misses here and there. After a decent coverage of the research, I expect to have enough understanding to discuss the challenges present in this task in a code-switched setting and its importance.
What is Language Identification, you ask?
Code-switching (and code-mixing) is the use of two or more languages in a conversation often employed by multilingual users in informal media like personal chats, Twitter, Facebook, Reddit. Language identification in the code-mixed text is the process of labeling each word with the language it belongs to. For example, in a Hinglish text (code-switching between Hindi and English), a sentence like Hindi ke liye it makes no sense should be labeled as Hindi\Hi ke\Hi liye\Hi it\En makes\En no\En sense\En.
- 2013 - Labeling the Languages of Words in Mixed-Language Documents using Weakly Supervised Methods
- 2013 - Query word labeling and Back Transliteration for Indian Languages: Shared task system description
- 2014 - Word-level Language Identification using CRF: Code-switching Shared Task Report of MSR India System (*this post*)
Publication
Word-level Language Identification using CRF: Code-switching Shared Task Report of MSR India System
Summary
- The objective is to identify the individual language of each word in a code-mixed text for the following four languages: English-Spanish (En-Es), English-Nepali (En-Ne), English-Mandarin (En-Cn), and Standard Arabic-Arabic (Ar-Ar) Dialects.
- They proposed a CRF-based approach inspired by the performance of CRFs in the previous work (discussed here.)
- The methods developed uses various token-based features which can be easily replicated across languages as they are not language-specific.
- The system relies on annotated data for supervised training, and also lexicon of languages, if available.
- The system achieves accuracy ranging from 80%-95% across the four language pairs.
Key Challenges Addressed
- Easy Replication: The features used for training the model are computed using the tokens themselves as they are based on the token context, language lexicon, other character features, and token n-grams. This simplicity enables the easy replication of the methods across various languages.
Constraints/Assumptions
- Since the two languages present in the documents are known, models are aware of the two languages a priori.
- The system assumes that the annotated training data is available for each language pair. In this work, the shared task organizers provided the annotated tweets.
Dataset
They considered the following four language pairs:
- English-Spanish
- English-Nepali
- English-Mandarin
- Standard Arabic-Arabic
- Released Data (Training and Testing)
-
Twitter data downloaded using the provided Ruby script. The following table summarizes the number of tweets downloaded for each language.
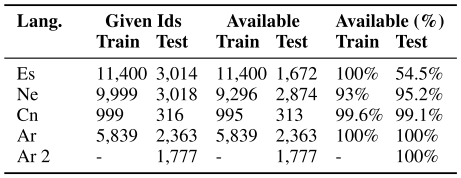
-
Pre-processing
- They excluded the deleted or private tweets from the training set.
- They fixed a few space tokenization errors by replacing them with an underscore.
-
- External Training Data
- Named Entities
- Word frequency lists from Corpus Portal for Search in Monolingual Corpora
- Available only for English and Spanish languages.
- Pre-processing: they removed the words containing special characters and numbers from the list.
Methodology
Character n-grams based Feature Engineering
The character n-gram classifiers are used as features in the final system.
- Objective: Two character n-grams classifiers for each language-pair
- Classes: For each language in the pair, they trained a model with binary class classification into two categories:
lang1andothers. - Training data:
- 6000 +ve examples randomly sampled from the training set for
lang1. - 6000 -ve samples randomly sampled from both the training set and word lists of multiple languages.
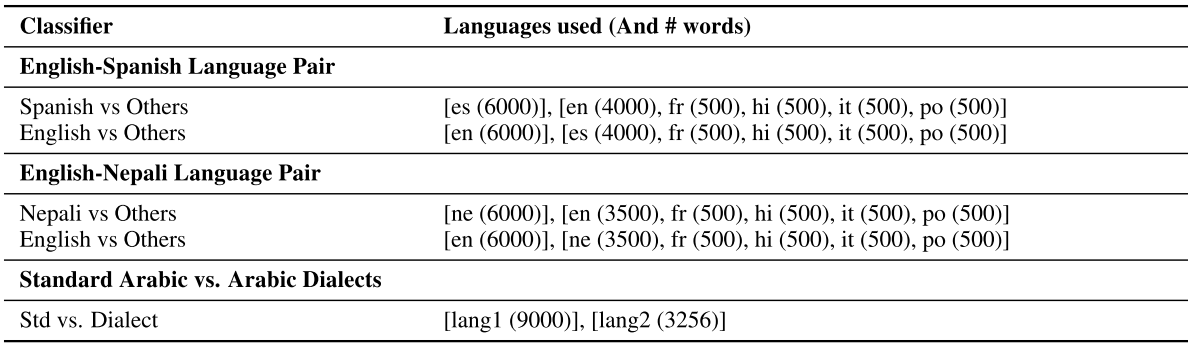
Data to train character n-gram classifiers - 6000 +ve examples randomly sampled from the training set for
- Eval data: Nothing mentioned
- Feature Engineering:
- Character unigrams
- Character bigrams
- Character trigrams
- Character 4-grams
- Character 5-grams
- Full word
- Feature Selection:
- All the features were selected, as past research showed them to be effective.
- Model Selection:
- The model considered based on previous research: Maximum Entropy (Logistic Regression)
- MALLET was used to train all the classifiers.
Final Labeling System
- Objective: Training a language identification system for each language pair.
- classes: For each language pair, the labeling system classifies each token into the following six classes:
lang1lang2mixed- tokens with morphemes from both lang1 and lang2.ne- named entitiesambiguous- a word whose label the model cannot determine with certainty in the given contextothers- smileys, punctuations, etc.
- Training Data
- Released data from the shared task (4 language pairs)
- Named entities dataset
- Word frequencies
- Eval data: Released data from the shared task (4 language pairs)
-
Feature Engineering: The following table shows the list of features created and finally selected for each language pair.
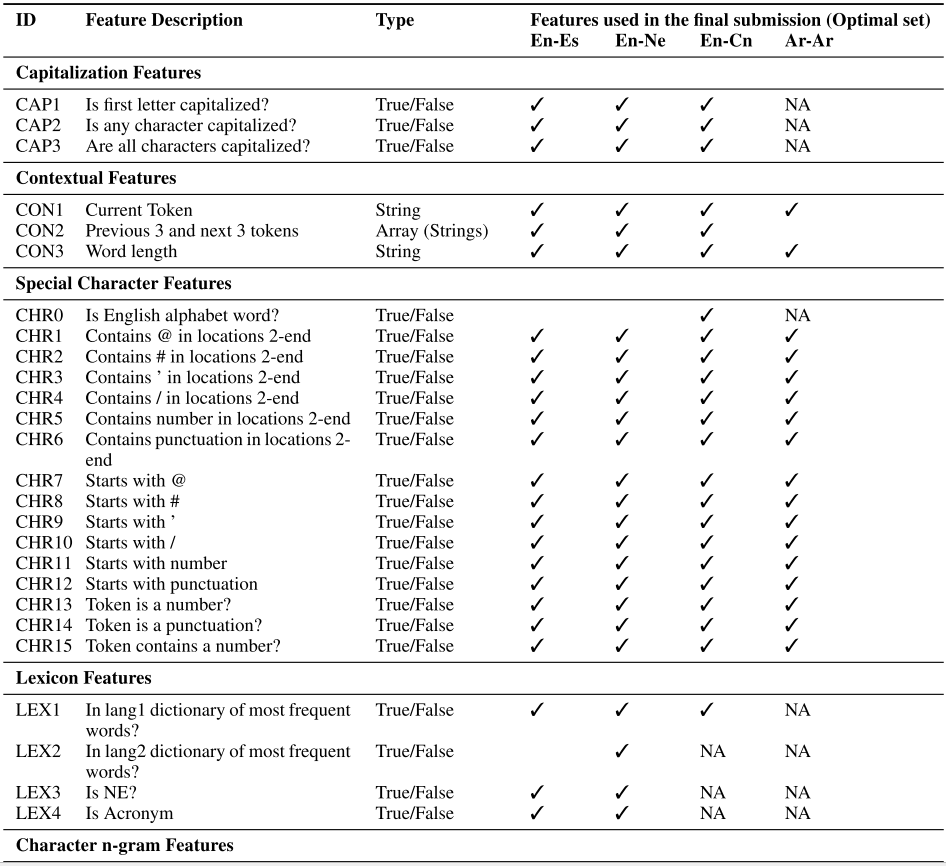
NA: features not applicable or not available. B/U: Bigram/Unigram feature including, the current token.
-
Feature Selection: Authors used the 3-fold cross-validation on released training sets to come up with the optimal features reported in the above table for each language pair.
- Using all the features of the previous tokens in the bigram context hurt the performance.
- The context feature of the previous three and next three tokens was useful.
- For En-Es, the character n-gram classifier feature was useful.
- For En-Cn, special character features were useful.
- For En-Ne, no particular feature set influenced the classification.
- Lexicon features were only available for English and Spanish.
- Model Selection:
- Based on the previous research in language identification, they considered the CRF++ model.
- MALLET was used to train all the classifiers.
-
Model Evaluation: The evaluation metric is the accuracy in a 3-fold cross-validation on the training sets. The following table gives the final accuracies for various combinations of features.
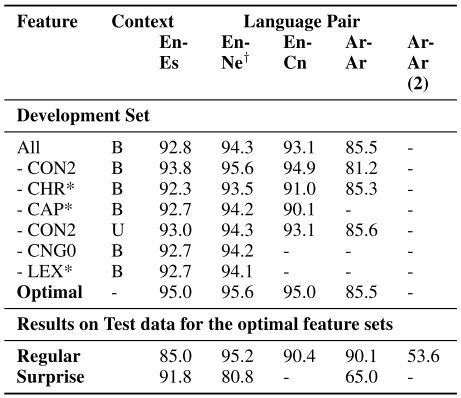
- Less accuracy of Ar-Ar system
- Lexicon features of dialectal Arabic were unavailable.
- Both dialects use the same script.
- Character n-gram classifier features reduced the accuracy. The hypothesis is that the dialects may not show a drastic difference in their character n-gram distributions.
- The En-Cn dataset had En words written in Roman script and Cn words in Chinese script. The feature
CHR0(is English alphabet word?) modeled this signal present in the script.
- Less accuracy of Ar-Ar system
-
Error Analysis:
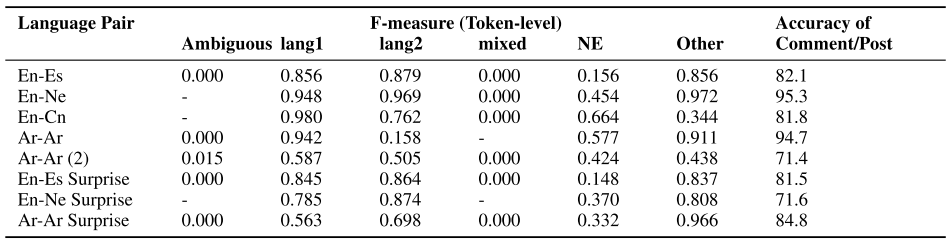
- Named Entities (NEs): The F-score of named entities is much lower than the F-scores of lang1 and lang2. Reasons for the discrepancy are:
- Lack of accurate NE identification systems.
- Lexicon features only available for English and Spanish.
- Informal nature of the sentences - not capitalized or spelled properly.
- We can ignore the
ambiguousandmixedclass errors because of their rarity in the datasets. They don’t contribute much to the accuracy of the system. - Reasons for the lower accuracy of Ar-Ar pair (
lang1: Arabic;lang2: Dialectal Arabic):- The model was only trained on context and word features (and not on lexicon or character n-grams.)
- Fewer words of dialectal Arabic in both training and testing: couldn’t train a reliable model.
- Due to distributional skew, the model learned to label the tokens as
lang1with a high probability. - F-score for
lang2is 15.8, and that oflang1is 94.2%: this shows that the identification oflang2was full of errors.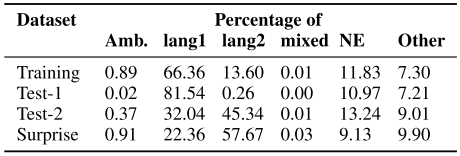
Distribution of classes in Ar-Ar released data sets.
- There was a drop in accuracy for En-Ne pair (
lang1: English;lang2: Nepali) in surprise data when compared to training and test data. Possible reasons are:- The difference in class distribution
- Genre/style of two datasets: surprise data contained song titles of Nepali songs. Many words were labeled as
lang2by the system, but gold labels identified them as NEs. This classification error was debatable. - Results were obtained on only 1,087 tokens, which can’t be used to make any strong claims or conclusions.
- Named Entities (NEs): The F-score of named entities is much lower than the F-scores of lang1 and lang2. Reasons for the discrepancy are:
Insights/Thoughts on the paper
- They formulated the problem as a sequence labeling problem. Can it be defined in some other way?
- The problem becomes trivial if languages present in the document do not share the character set. I discussed this in the first paper in this series, and we can see it in action in the current work. For the pair En-Cn, because the Chinese words are present in the original script, it became efortless for the model to identify the language.
- The authors performed a lot of feature engineering (token context, lexicon, derived from the tokens, n-grams) and exhaustively evaluated the models on those features for each of the language pair. They picked the feature set utilized in the previous research work and built more on top of them. They found the importance of different features for different languages.
- The employed model is not complex, and the features are simple and easily derived from the tokens themselves. The training data used was also small. As the authors pointed out, the developed methods are easily replicable for other languages. They are scalable to label large amounts of data in production systems too.
- The system should have high throughput, as the classification is built with simple features and compute efficient models.
- The described process is supervised because:
- The training data employed were annotated.
- It also relies on the lexicon of languages and is subject to the availability of those lexicon resources. Where ever the lexicon resources were not available, it hurt the performance of the classifiers.
There was little data available for training. And, many of the considered languages have many speakers and thus have a lot of language resources available. What about the low-resources languages? In the last two papers, authors had used monolingual corpora to train their models, and hence there was no need for annotated data, but here the situation is different. Annotating data for training purposes is prohibitive. Can we cheaply create the annotated data?
- Detecting Named Entities (NEs) was the most challenging problem faced by researchers. The authors in the first paper suggested that if we create a separate class for NEs, then the accuracy of the system should improve. In the current work, the authors did this. It seems like the accuracy has improved, but there were still errors in differentiating between a language token and a NE. Here also, the authors suggest that a better NE detection system will improve the system.
- The researchers reported their system accuracies for each of the language pairs in clear terms. There was no ambiguity in the language used to describe the methods and the results.
- The authors only considered the five languages which were part of the task. Since the proposed methods are language agnostic, we can extend them for other languages as well. I think it is easier said than done for the following reasons:
- There should be annotated data available for the other languages, which is not always guaranteed as it’s expensive to do the annotation.
- The lexicon resources are also not guaranteed to be available. We saw the effect of this on the classification accuracy of the Ar-Ar language pair. It would have impacted the accuracy of En-Cn as well if the script had been the same.
- If the authors had considered transliterated code-switched text, they would never found the lexicon resources for those languages.
- Since the shared task description aimed to label the tweets, this methodology is suitable for short-text-like content generated on social media. Although, the researchers didn’t discuss and work on challenges like word normalization (misspellings or acronyms) that often pervade social media text.
- The data and language pairs considered by the authors contained code-mixed data, but not transliterated data except maybe the En-Ne language pair. The presented methods have worked well for the code-switched data without adding any other complexities in the mix.
- Any discussions on the transliteration were completely skipped.