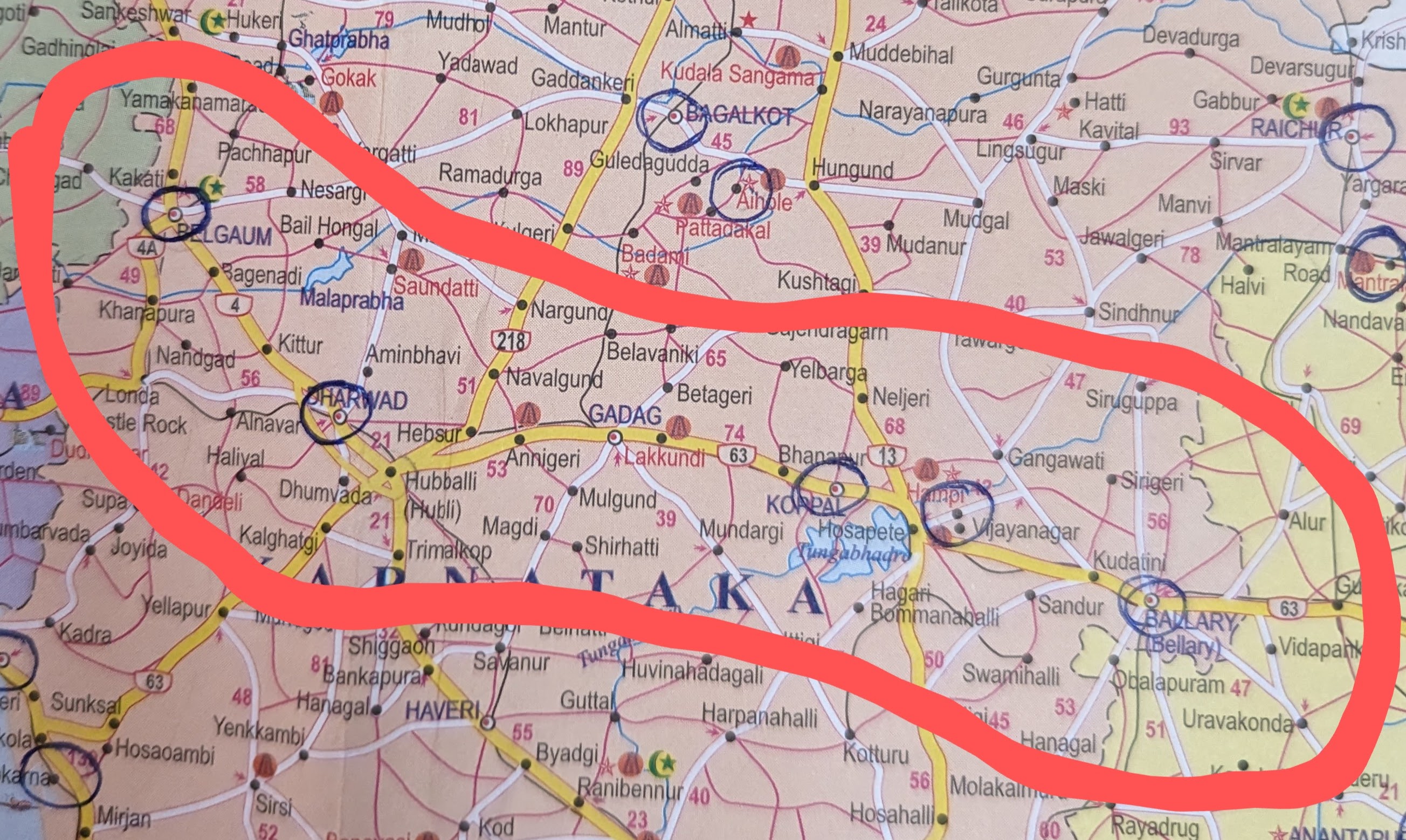
Outline
Normal & Lognormal Distributions
The normal distribution is also called the bell curve or Gaussian distribution. The bell height represents the mean position, and the bottom width of the bell represents the spread of values (standard deviation). Thus, the shape changes as we change mu (\(\mu\)) and sigma (\(\sigma\)). The \(\mu\) is the mean or average of the sample, and \(\sigma\) is the standard deviation. We denote a normal distribution as:
\[{\mathcal {N}}(\mu ,\sigma ^{2})\]Find more details about the normal distribution on Wikipedia. Here are two ways of defining a normal distribution in Python.
- Using python stdlib
1
2
3
from statistics import NormalDist
mu, sigma = 5, .5
norm_dist = NormalDist(mu, sigma)
- Using scipy
1
2
3
import scipy.stats as stats
mu, sigma = 5, .5
norm_dist = stats.norm(mu, sigma)
We get a lognormal distribution when we apply exponentiation to the normal distribution. The result is a lopsided curve. It means that there is a longer tail on the right side, where larger values occur. We denote the lognormal distribution as follows:
\[{\displaystyle \ X\sim \operatorname {Lognormal} \left(\ \mu _{x},\sigma _{x}^{2}\ \right)\ }\]Since the log of the lognormal distribution is a normal distribution, we can denote the relationship as follows:
\[{\displaystyle \ln(X)\sim {\mathcal {N}}(\mu ,\sigma ^{2})}\]Find more details about the lognormal distribution on Wikipedia. We define a lognormal distribution in Python as follows. The Python stdlib does not have a lognormal implementation.
1
2
3
4
import numpy as np
import scipy.stats as stats
mu, sigma = 5, .5
norm_dist = stats.lognorm(s=sigma, scale=np.exp(mu))
Note: the scipy.stats.lognorm takes mu and sigma of the underlying normal distribution from which we derive the lognormal distribution. While providing the scale parameter, we take the exponentiation of the mean of the normal distribution. I found the documentation inadequate in explaining the parameters. This SO question has answers that discuss the meaning of the parameters.
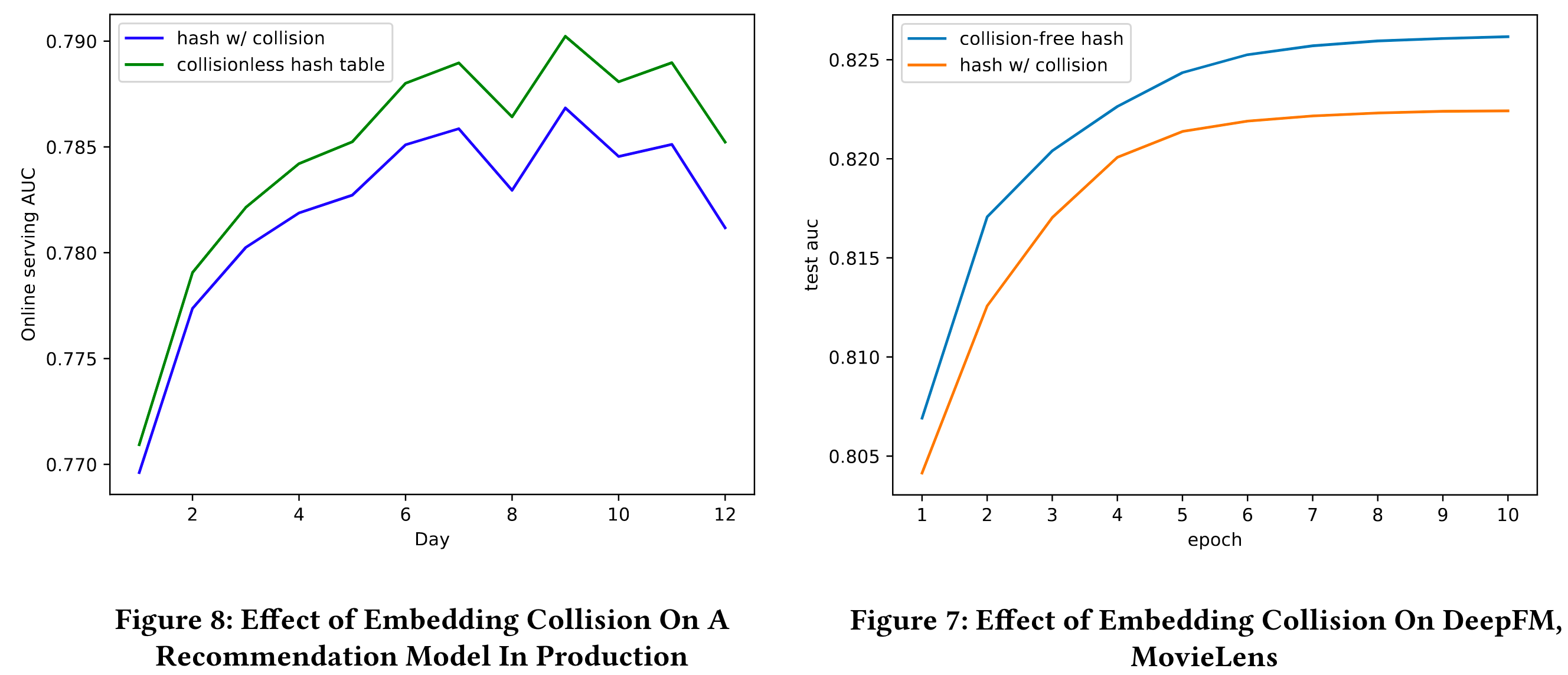
Here is how both the distributions look for the same mu (\(\mu\)) and sigma (\(\sigma\)).
Code to generate the below plot.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
# all distributions
mu, sigma = 5, .5
norm_d1 = NormalDist(mu, sigma)
lognorm_d1 = stats.lognorm(s=sigma, scale=np.exp(mu))
lognorm_d1.mu, lognorm_d1.sigma = mu, sigma
mu, sigma = 5, 1
norm_d2 = NormalDist(mu, sigma)
lognorm_d2 = stats.lognorm(s=sigma, scale=np.exp(mu))
lognorm_d2.mu, lognorm_d2.sigma = mu, sigma
mu, sigma = 4, 0.3
norm_d3 = NormalDist(mu, sigma)
lognorm_d3 = stats.lognorm(s=sigma, scale=np.exp(mu))
lognorm_d3.mu, lognorm_d3.sigma = mu, sigma
# norm y
x = np.linspace(0, 10, 500)
norm_y1 = np.array([norm_d1.pdf(i) for i in x])
norm_y2 = np.array([norm_d2.pdf(i) for i in x])
norm_y3 = np.array([norm_d3.pdf(i) for i in x])
# lognorm y
x = np.linspace(0, 800, 500)
lognorm_y1 = np.array([lognorm_d1.pdf(i) for i in x])
lognorm_y2 = np.array([lognorm_d2.pdf(i) for i in x])
lognorm_y3 = np.array([lognorm_d3.pdf(i) for i in x])
# Set the figsize
fig1, ax1 = plt.subplots(figsize=(6, 4))
ax1.plot(x, norm_y1, label=f"mu = {norm_d1.mean}; sigma = {norm_d1.stdev}")
ax1.plot(x, norm_y2, label=f"mu = {norm_d2.mean}; sigma = {norm_d2.stdev}")
ax1.plot(x, norm_y3, label=f"mu = {norm_d3.mean}; sigma = {norm_d3.stdev}")
ax1.legend()
fig2, ax2 = plt.subplots(figsize=(6, 4))
ax2.plot(x, lognorm_y1, label=f"mu = {lognorm_d1.mu}; sigma = {lognorm_d1.sigma}")
ax2.plot(x, lognorm_y2, label=f"mu = {lognorm_d2.mu}; sigma = {lognorm_d2.sigma}")
ax2.plot(x, lognorm_y3, label=f"mu = {lognorm_d3.mu}; sigma = {lognorm_d3.sigma}")
ax2.legend()
plt.show()
fig1.savefig('norm_dist.svg', format='svg', dpi=1200, bbox_inches='tight')
fig2.savefig('lognorm_dist.svg', format='svg', dpi=1200, bbox_inches='tight')
NormalDist.pdf() we can also use numpy.random.Generator.normal to get a normal distribution sample and plot a histogram. Similarly, for lognormal distribution, instead of stats.lognorm.pdf(), we can use numpy.random.Generator.lognormal.


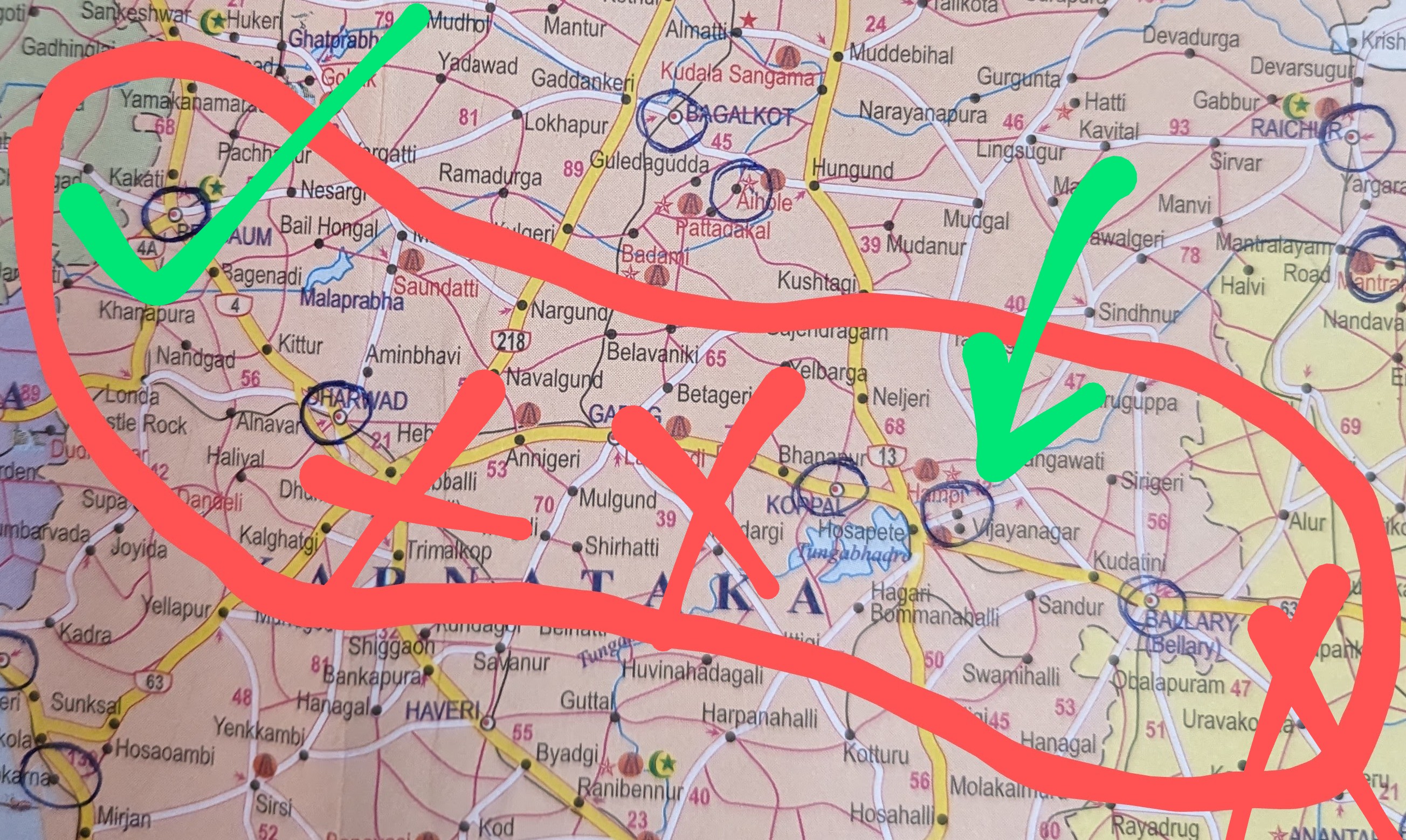
Lognormal to Normal
As mentioned in the previous section, normal distribution is just a log of the lognormal distribution. So, if \({\displaystyle \ X\sim \operatorname {Lognormal} \left(\mu _{x},\sigma _{x}^{2} \right)}\), then \({\ \displaystyle \ln(X)\sim {\mathcal {N}}(\mu ,\sigma ^{2})}\).
Let us understand this by code.
1
2
3
4
5
6
7
8
9
import numpy as np
rng = np.random.default_rng()
mu, sigma = 5, .5
lognorm_samples = rng.lognormal(mu, sigma, 10000)
# take the log of lognorm samples to derive the normal dist.
norm_samples = np.log(lognorm_samples)
print(norm_samples.mean(), norm_samples.std())
5.005339216906491 0.4934326302969564
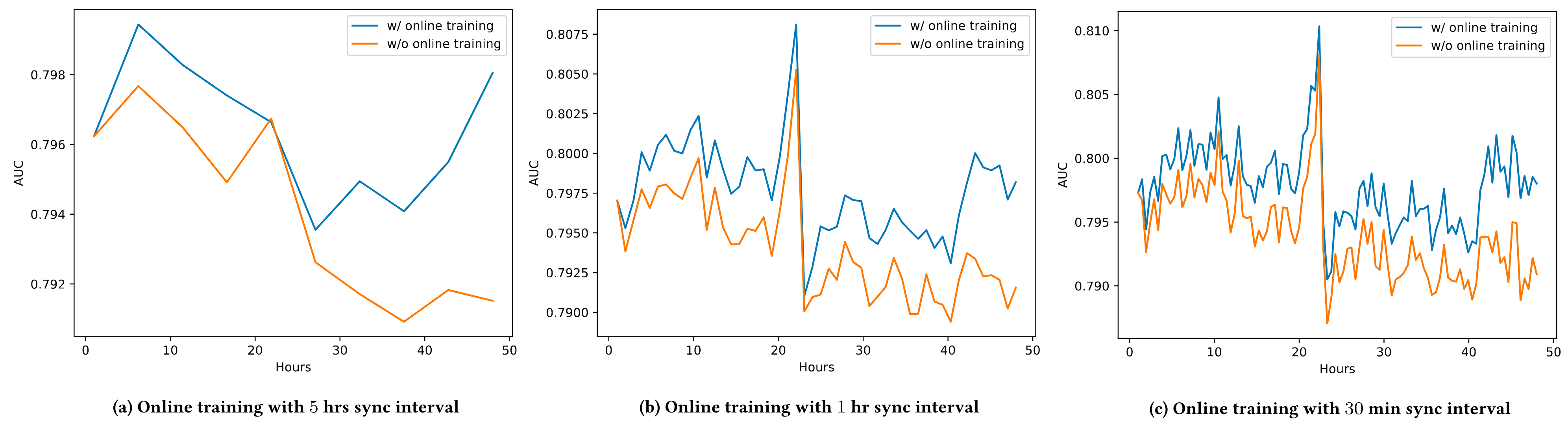
The parameters (mean and std) of the derived normal distribution (line 7) are the same as the original parameters we provided to the lognormal dist (line 5).
Code to generate the below plots
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# log normal dist
fig1, ax1 = plt.subplots(figsize=(5, 3))
ax1.hist(lognorm_samples, bins=50, alpha=0.7, density=True, color="orange")
x1 = np.linspace(0, 800, 500)
lognorm_d = stats.lognorm(s=sigma, scale=np.exp(mu))
lognorm_y = np.array([lognorm_d.pdf(i) for i in x1])
ax1.plot(x1, lognorm_y, label=f"mu = {mu}; sigma = {sigma}")
ax1.legend()
# normal dist
fig2, ax2 = plt.subplots(figsize=(5, 3))
ax2.hist(norm_samples, bins=50, alpha=0.7, density=True, color="orange")
x2 = np.linspace(0, 7, 500)
norm_d = stats.norm(mu, sigma)
norm_y = np.array([norm_d.pdf(i) for i in x2])
ax2.plot(x2, norm_y, label=f"mu = {mu}; sigma = {sigma}")
ax2.legend()
plt.show()
fig1.savefig('lognorm_dist2.svg', format='svg', dpi=1200, bbox_inches='tight')
fig2.savefig('norm_dist2.svg', format='svg', dpi=1200, bbox_inches='tight')


Conclusion: to convert from a lognormal to normal, take the logarithm of the lognormal sample.
Normal to Lognormal
If the logarithm of a lognormal distribution is normally distributed, then the reverse will also be true. That is, the exponential of a normal distribution will give us a lognormal distribution. In notation, if \({\displaystyle Y\sim {\mathcal {N}}(\mu ,\sigma ^{2})}\), then \({\ \displaystyle \exp(Y)\sim \operatorname {Lognormal} \left(\mu _{x},\sigma _{x}^{2} \right)\ }\).
Let’s again understand this through code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import numpy as np
import scipy.stats as stats
rng = np.random.default_rng()
mu, sigma = 5, .5
norm_samples = rng.normal(mu, sigma, 10000)
# take the exp of norm samples to derive the lognormal dist.
lognorm_samples = np.exp(norm_samples)
# fit a lognorm distribution to get the mean and std dev
shape, loc, scale = stats.lognorm.fit(lognorm_samples)
mean, stddev = np.log(scale), shape
print(mean, stddev)
4.984256782660331 0.5067622675605842
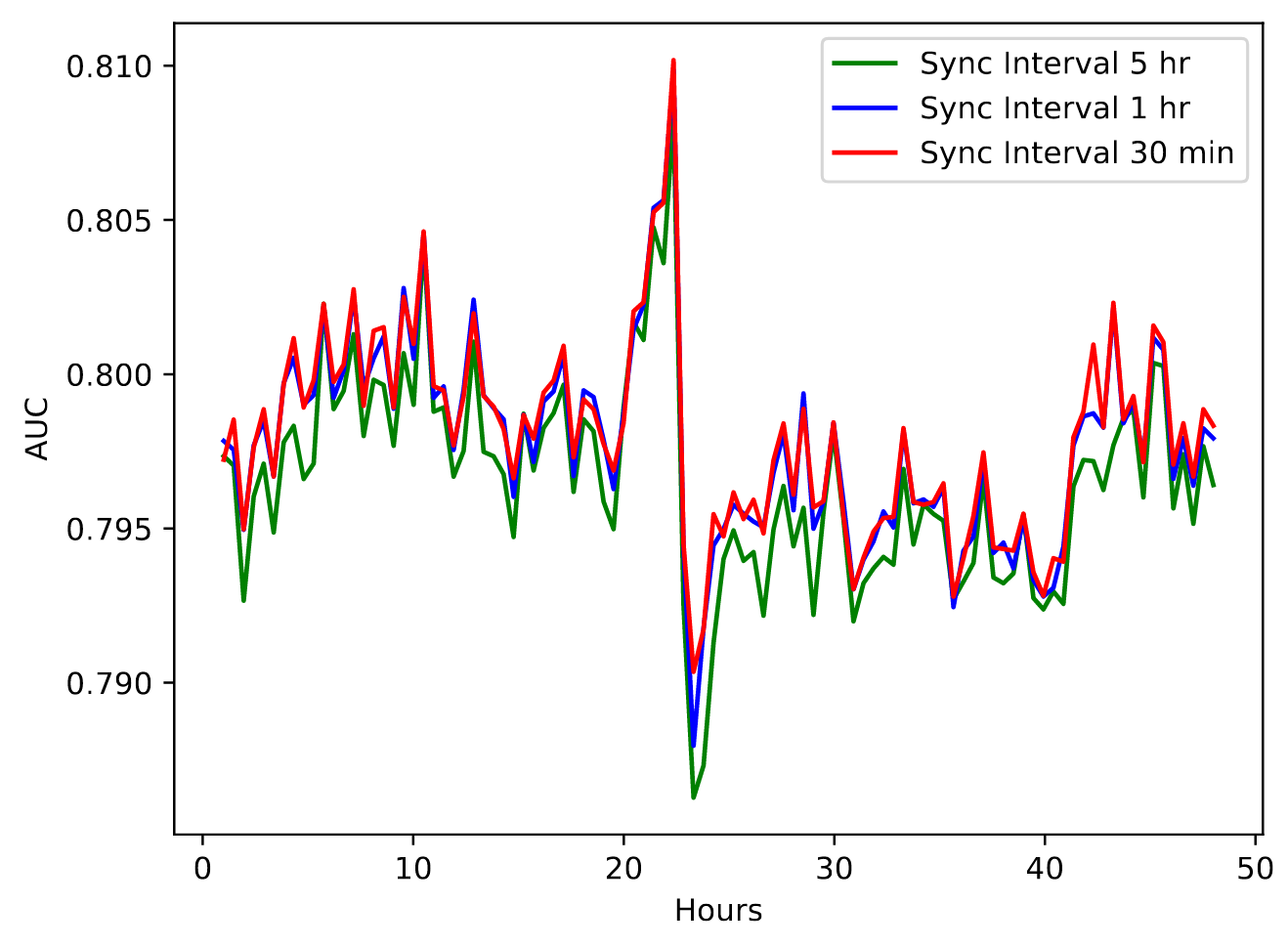
The parameters (mean and std) of the derived lognormal distribution (line 10) are the same as the original parameters we provided to the normal dist (line 6). Note that we used the [scipy.stats.lognorm.fit] method to fit the lognorm distribution on the data. It gives us the following three parameters: loc, shape and scale. The shape is same as standard deviation. To get the mean, we have to take the logarithm of the scale. We did not have to do this when we converted the lognormal to a normal distribution (previous section) because we can directly get the params (mean and std). Read this SO answer for more details.
Code to generate the below plots
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# normal dist
fig1, ax1 = plt.subplots(figsize=(5, 3))
ax1.hist(norm_samples, bins=50, alpha=0.7, density=True, color="orange")
x1 = np.linspace(0, 7, 500)
norm_d = stats.norm(mu, sigma)
norm_y = np.array([norm_d.pdf(i) for i in x1])
ax1.plot(x1, norm_y, label=f"mu = {mu}; sigma = {sigma}")
ax1.legend()
# lognormal dist
fig2, ax2 = plt.subplots(figsize=(5, 3))
ax2.hist(lognorm_samples, bins=50, alpha=0.7, density=True, color="orange")
x2 = np.linspace(0, 800, 500)
lognorm_d = stats.lognorm(s=sigma, scale=np.exp(mu))
lognorm_y = np.array([lognorm_d.pdf(i) for i in x2])
ax2.plot(x2, lognorm_y, label=f"mu = {mu}; sigma = {sigma}")
ax2.legend()
plt.show()
fig1.savefig('norm_dist3.svg', format='svg', dpi=1200, bbox_inches='tight')
fig2.savefig('lognorm_dist3.svg', format='svg', dpi=1200, bbox_inches='tight')


Conclusion: to convert from a normal to lognormal, take exp of the normal sample.
Conclusion
We started with the Normal and Lognormal distributions and with their definition in Python. We converted each of the distributions into the other. It took me some effort to figure out how to do the conversion. With this post, I tried to demystify the confusion.
If you are interested in how other distributions look, your search is over. This SO answer has visualisations of all the distributions available in scipy.stats.
Update: 18th Jan: Someone asked me the following question on reddit.
For what purpose are you converting between normal and lognormal? The two functions share the same parameters but thats about it. ln(data) is a non-destructive transformation but the process can obscure patterns just as often as it reveals them. Certain advanced statistical tests that require a normal distribution cannot necessarily have the results applied to the lognormal data.
This stranger is correct that patterns are obscured, or rather, some other patterns come up after log transformation. Although, in my case, it did not matter.
I wanted to match the customers with the items that are within the customer spending range. The formulation was that if I have customer and outlet distributions, then I can match these distributions or get the overlap to get the match percentage. This match percentage will then be used on top of relevance scores.
Looking at the customer’s spend history, I saw that the distribution was lognormally distributed. A similar trend was observed in the restaurant’s order history. Since, computing the overlap in the production env was easier with the normal distributions, I was okay with the conversion. I will cover this in more detail in a future post.
]]>