[Summary] Monolith: Real-Time RecSys With Collisionless Embeddings
Paper link: Monolith: Real Time Recommendation System With Collisionless Embedding Table
Abstract
- Real-time RecSys are important when customer feedback is time sensitive (eg: TikTok short-video ranking).
- The production-scale DL frameworks (PyTorch, TensorFlow) are designed with separate batch-training and model serving stages. This makes online training difficult.
- Presenting Monolith for online training:
- Collisionless embeddings with expiry parameter and frequency filtering to reduce memory footprint
- Online training architecture with fault-tolerance in parameter server
- Part of BytePlus Recommend.
Data in RecSys
- For many businesses driven by RecSys, better CX = real-time RecSys.
- Information from a user’s latest interaction become primary input as it’s the best signal of a user’s future interest and behavior.
- DL in RecSys
- Wide & Deep Learning for Recommender Systems, 2016
- Deep Neural Networks for YouTube Recommendation, 2016
- The Architectural Implications of Facebook’s DNN-Based Personalized Recommendation, 2020
- XDL: an industrial deep learning framework for high-dimensional sparse data, 2019
- Kraken: Memory-Efficient Continual Learning for Large-Scale Real-Time Recommendations, 2020
- AIBox: CTR Prediction Model Training on a Single Node, 2019
- DL in industry RecSys faces problems because of the real-world data.
- Data is different from CV/NLP tasks:
- Features are mostly sparse, categorical, and dynamically changing.
- Concept Drift: Training data distribution is non-stationary. (ref: A survey on concept drift adaptation, 2014)
Sparsity and Dynamism
- RecSys data has a lot of categoricals (eg: customer id, item id, item type, etc)
- Categorical features are sparse (eg: a user only buys limited items).
- Feature engineering of categorical features: map them to a high-dimensional embedding space.
- Issues with embeddings for categoricals:
- Users and items are orders of magnitude larger than word-piece tokens in LMs. This enormous embedding table would hardly fit in memory.
- As more users and items are added, the size would increase further.
- Current solution: Low-collision hashing to reduce the memory footprint and to allow the growing of IDs (user or item)
- Assumptions:
- Embedding table is distributed evenly in frequency. It is rarely true because only a small group of users or items have high frequency.
- Collisions are harmless to model output. But it is detrimental because organic growth in embedding table size leads to more collisions.
- Ref: Core Modeling at Instagram
- Ref: Deep Neural Networks for YouTube Recommendation, 2016
- Assumptions:
- Thus, natural and constant demand to elastically adjust the users and items a RecSys tries to book-keep.
Concept Drift
- Underlying user distribution is non-stationary: user interests change with time (even during sessions).
- More recent data is more likely to predict change in user’s behavior.
- Mitigating concept drift: serving model should be updated as close to real-time as possible to reflect the latest user interests.
Parameter Server (PS)
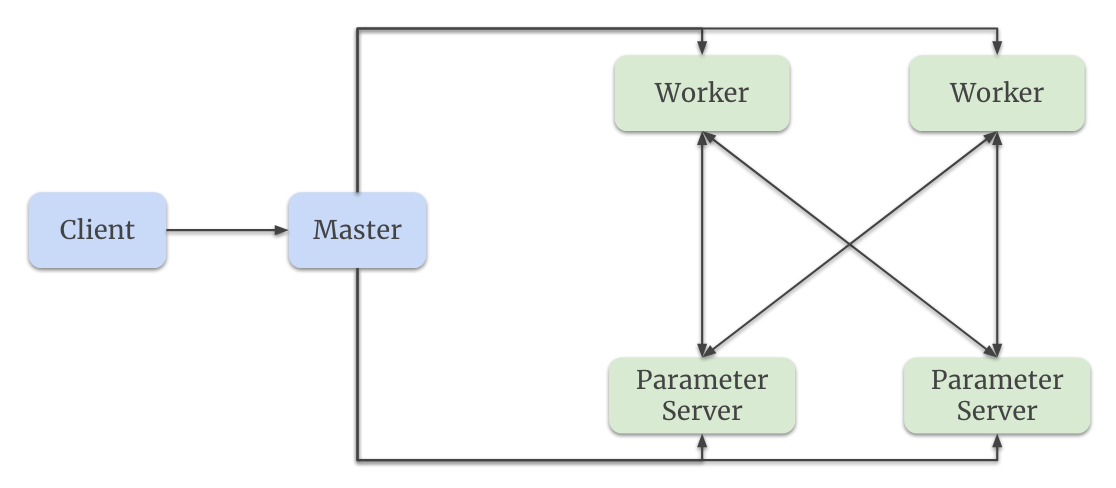
- Worker machines compute the gradients.
- PS machines store parameters and updates them according to gradients.
- Two kinds: 1) training PS; and 2) serving PS. Training PS holds training parameters. Once training is complete, it is synced to Serving PS.
- Two types of parameters:
- Dense: weights/variables in DNN; and
- Sparse: embedding tables corresponding to sparse (categorical) features.
- Since both dense and sparse features are part of the TensorFlow Graph, Monolith stores them on the PS.
- The
tf.Variableis for dense variables. For sparse variables, authors created HashTable operations.
Hash Table
- Representation of embeddings in TensorFlow and its limitation
- The tf.Embedding layer uses variables to represent the dense embedding vectors. (the embedding matrix is of type
Variable.) - The
Variableconstruct freezes the shape of the matrix throughout the training/serving process. Thus, is it a fixed-size embedding. - As IDs increase with time, since the table size is fixed, ID collisions (while updating/using the dense embedding vector) would increase.
- The tf.Embedding layer uses variables to represent the dense embedding vectors. (the embedding matrix is of type
- Authors implemented a new key-value HashTable.
- Hashing algorithm: Cuckoo hashing[Visualization + Explanation - Youtube]
- Lookup:
O(1); Insertion: amortizedO(1) - Implemented as a TensorFlow resource operation (it likely means a TensorFlow custom layer).
- Lookups and updates are implemented as native TF operations.
- Naive insertion: insert every new ID in the HashTable. Will deplete memory quickly.
- Insertion by frequency
- IDs (user, item, etc) have long-tail distribution.
- Infrequent IDs will have underfit embeddings because of less training data.
- Model quality will not suffer from removal of these IDs.
- Filter by a threshold of occurrences before insertion.
- The threshold is a tunable hyperparameter for each model.
- Also use a probabilistic filter (didn’t expand on it)
- Insertion by staleness
- Many IDs are never visited (user inactive, out-of-date item)
- Set a expiry time for each ID.
- The expiry time is tunable for each embedding table: different tables will have different sensitivity to historical information.
Model Training
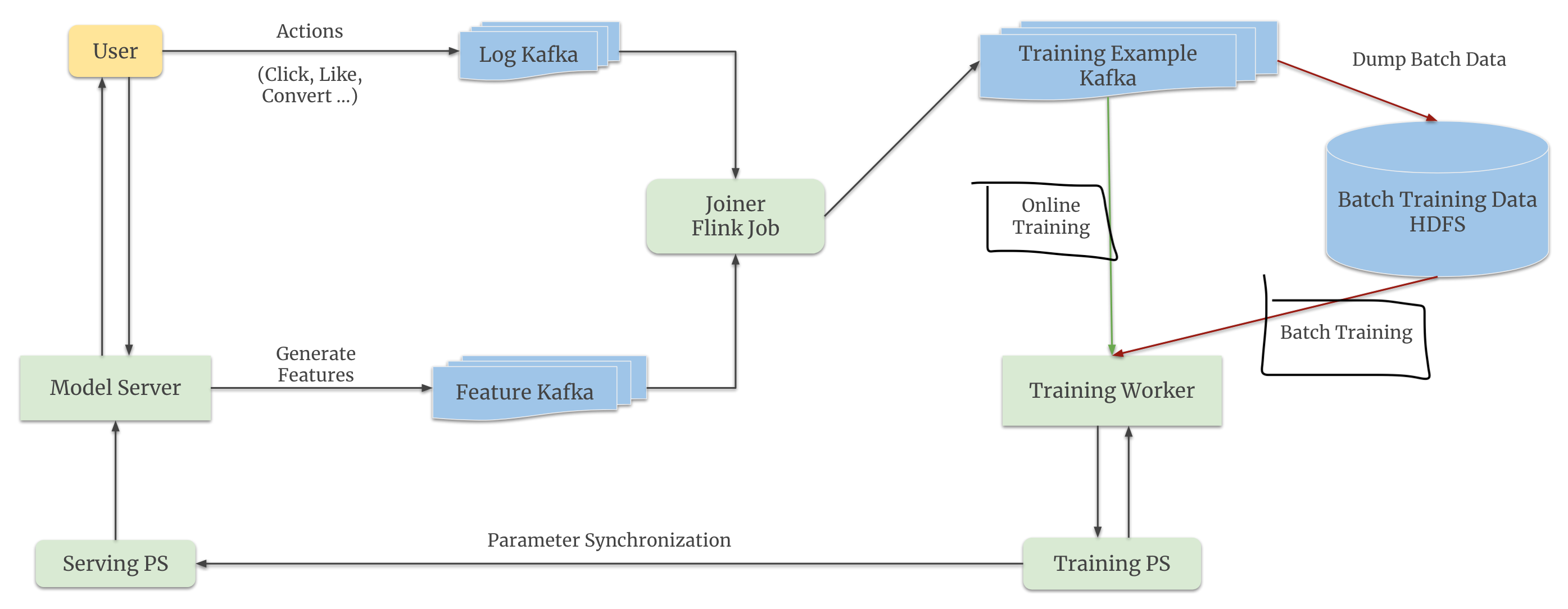
- Engineering steps
- User logs (click, like, buy) go to Kakfa.
- Model features are present in the another Kafka (didn’t discuss what features)
- Create the training example by joining the features with user logs using a Flink job.
- First, check for the data in in-memory cache;
- If not found, then go to on-disk key-value storage (happens in cases when user feedback arrives after days and in-memory cache is cleared to free-up the memory)
- Push the created training example to a 3rd Kafka queue.
- Push data from the 3rd queue to HDFS for offline training mode.
- Trigger online or offline training
- Push the updated parameters to the Training PS
- Sync the Serving PS with the Training PS
- Batch training stage
- Ordinary TF training loop
- Training worker reads a mini-batch from storage.
- Request parameters from PS.
- Compute a forward and backward pass.
- Push the updated parameters to training PS.
- Only train for a single pass over the data. (to mimic the online training phase?)
- Useful when: model architecture is modified and require retraining.
- Ordinary TF training loop
- Online training stage
- Triggered when the model is online.
- Steps:
- Training worker consumes real-time data from a Kafka queue.
- Update the parameters in the training PS.
- Push the updated parameters to training PS.
- Negative sampling
- To handle the highly skewed negative to positive sample ratio.
- It changes the underlying distribution of the trained model: higher probability of making positive predictions.
- Apply log-odds correction during serving to ensure the online model is an unbiased estimator of the OG distribution. (ref: Nonuniform Negative Sampling and Log Odds Correction with Rare Events Data, 2021)
- Parameter sync. between training and serving PS
- Production models are TB in size.
- Replacing all the parameters will take time.
- It will also consume network bandwidth and extra storage (need to store the new parameters before replacing the old ones).
- Solution: incremental periodic parameter sync.
- Sparse features (aka embedding tables): Sync the keys whose vectors updated during the last 1 minute.
- Dense variables (aka model weights): model weights move much slower because the momentum-based optimisers take more time to build momentum over the big data. Thus the sync frequency is 1-day. The authors found the stale weights tolerable.
- Fault tolerance: periodic model snapshots
- Trade-off between: model quality (because of the loss of recent updates) and computation overhead (copy-pasting TB of data)
- Snapshot frequency: 1-day. Experiments revealed that performance degradation was tolerable.
Evaluation
(I will skip the experiment setup and jump over to the results.)
The Effect of Embedding Collision
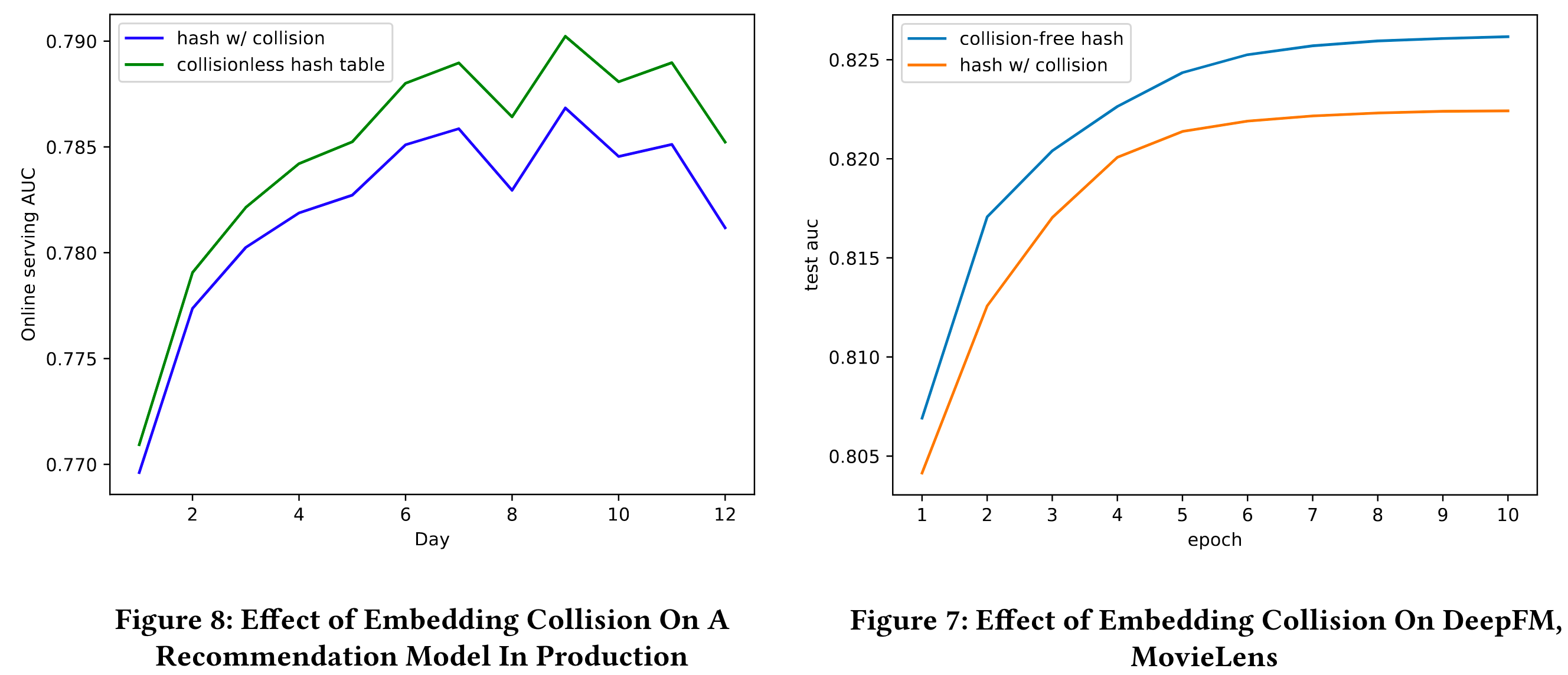
- Model with collisionless embedding vectors consistently outperform the one with collision.
- Independent of training epochs and concept drift (non-stationary training data)
Online Training vs Batch Training
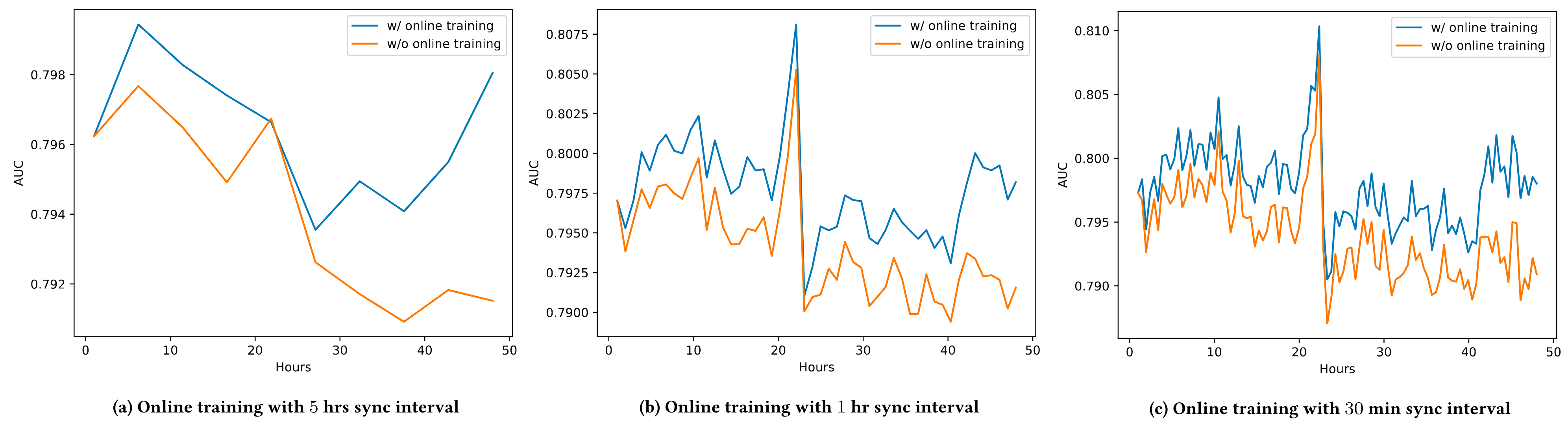
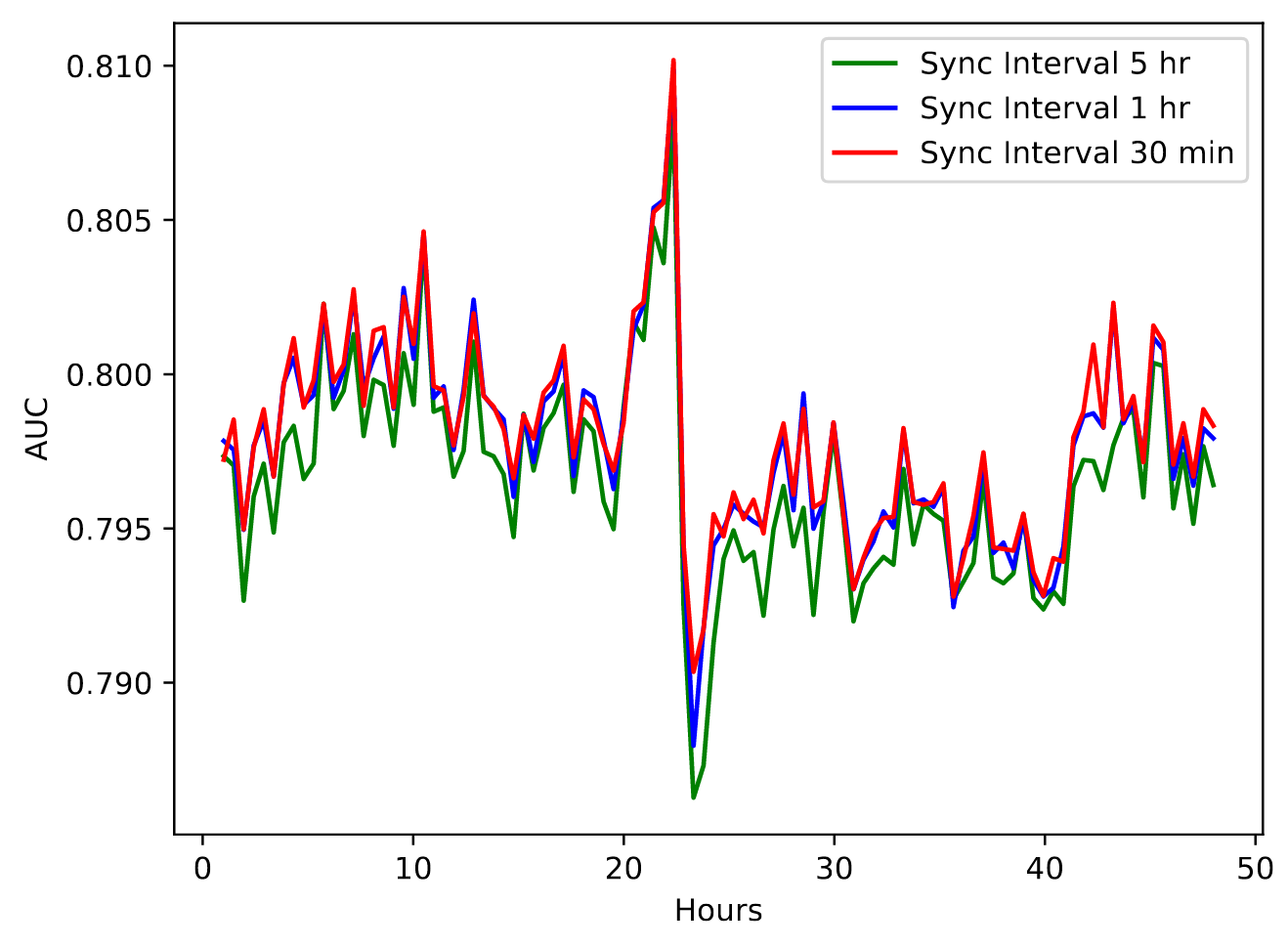
- Online training has better performance than the batch training.
- AUC of online training models: evaluated by the following shard of data.
- AUC of batch training models: evaluated by each shard of data (?)
- General AUC delta ranged between 0.20 (5hr interval) to 0.40 (30 min interval).
- Smaller parameter sync interval (or higher parameter sync freq.) performs better than the larger intervals.
- Based on these results, best sync frequency for sparse features that the systems could endure was 1 minute.
- Assuming 100,000 IDs with 1024 vector size are updated each minute: ~400 MB (4 KB * 100,000) network transfer per minute.
- Sync frequency for dense features is 1-day (every midnight) as they update slowly.
Is the 2nd figure correct? The 5hr sync interval model should degrade till the sync happens. After sync, it should have similar AUC as other models. It should then degrade again from that point until the next sync. That is not happening here. What am I missing?
PS Reliability
- Hypothesis: minute-level parameter syncing should mean frequent snapshots.
- Wrong. Observed no loss in the model quality even with 1-day snapshot interval.
-
Below excerpt explains the reason:

- Lesson: don’t take frequent snapshots and save resources.
Summary Conclusion
- The paper proposed the following:
- Cuckoo HashMap based collisionless embedding tables
- Online training and parameter sync architecture
- With extensive experimentations (both offline and online) they showed that:
- Collisionsless embedding table has a positive impact on the model quality (AUC gains ranged from 0.20% to 0.40%)
- Online training performs better than batch training in RecSys setting.
- Higher parameter sync freq is better (1 minute for prod systems); and
- It is okay to have a smaller parameter snapshotting frequency (1-day for prod systems)
- This paper was a write-up of engineering tricks that ByteDance employed to build their RecSys.
- The few nuggets of ML that I noticed:
- Apply log-odds correction to the data in online serving to make up for negative sampling.
- Online real-time model at ByteDance is a multi-tower architecture where each tower is responsible for learning a special kind of user behavior. (Is than an allusion to multi-objective ranking through different towers?)
Overall, this paper adds to my belief that a successful system requires clever engineering.