[Summary] Deep Recurrent Neural Networks for OYO Hotels Recommendation
Paper link: Deep Recurrent Neural Networks for OYO Hotels Recommendation
Abstract
- A hybrid model with two parts:
- Embedding generation: generate implicit embeddings of properties.
- Deep prediction and ranking model.
- The model performed well over the existing collab-filtering model.
Situation/Context
- OYO’s current recommendation system
- Graph-based Collaborative filtering model
- Optimised on browsing data as user feedback
- Objective: CTR
- DL provides an opportunity to improve the system.
Lit Review
- Conventional RecSys algos:
- Collab-filtering,
- Content-based, and
- Hybrid
- YouTube’s 2016 paper has demonstrated that DL-based RecSys can give SOTA results on high-volume data.
- MF only considers the linear combination of user and item latent vectors. Whereas, DL can capture non-linear user-item relationships.
- DL reduces the feature engineering efforts.
- RNN facilitate temporal behaviour of user-item interactions: useful for session-based sequential recommendations. Conventional algos don’t capture this.
- Research on modelling user behaviour sequences using LSTM or GRUs
- Sequential User-based Recurrent Neural Network Recommendations, 2017
- Recurrent Neural Networks with Top-k Gains for Session-based Recommendations, 2018
- Session-based Recommendations with Recurrent Neural Networks, 2016
- Neural Attentive Session-based Recommendation, 2017
- Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks, 2017
- Recurrent Recommender Networks, 2017
- A Dynamic Recurrent Model for Next Basket Recommendation, 2016
- This Airbnb paper (summary) takes the sequence of listing ids clicked by the users and trains a skip-gram word2vec model on it. And then rank using these embeddings.
- The authors of this paper mention that they improve it by adding entity features along with click data.
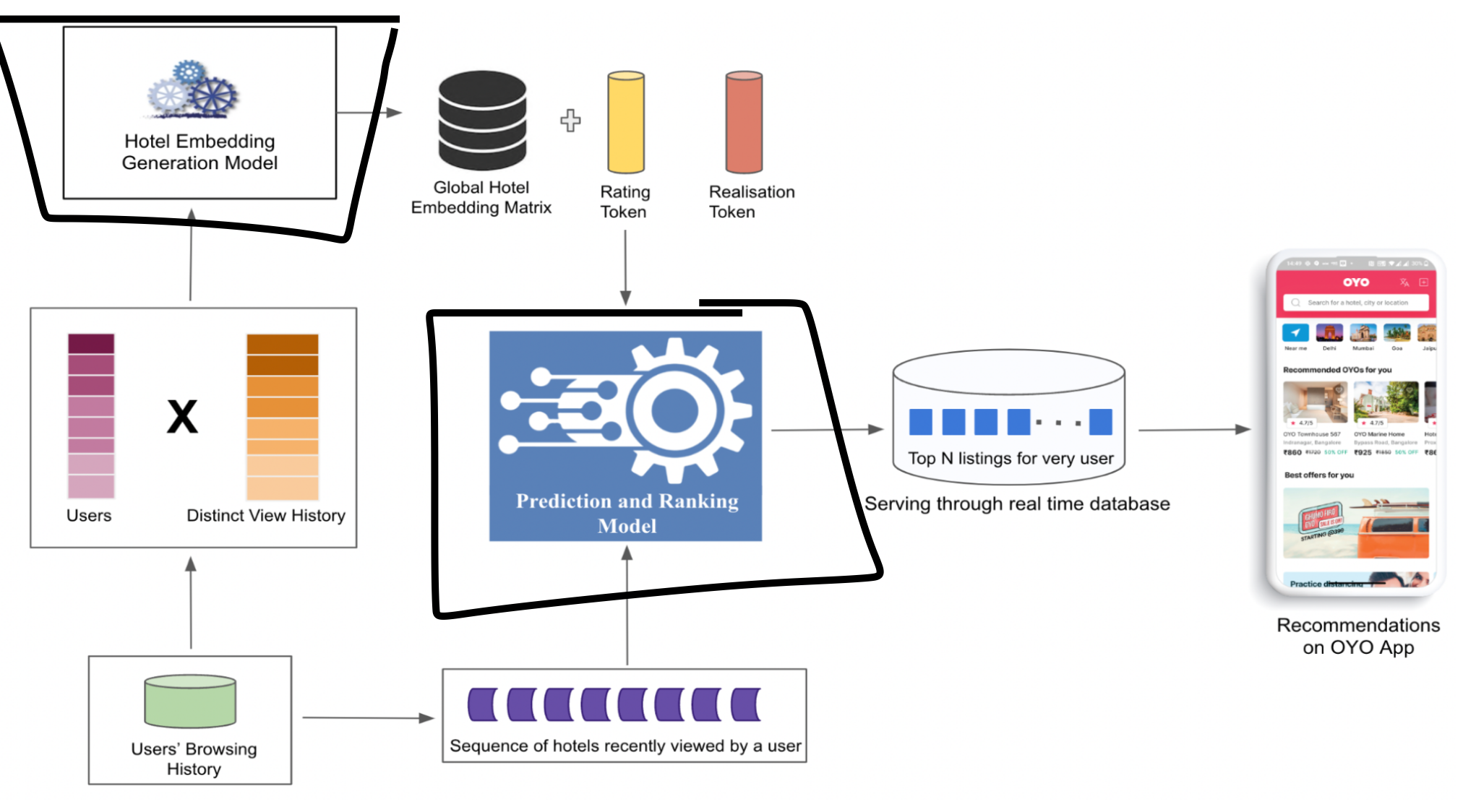
Methodology
- Embedding generation: generates embeddings of the hotels (intermediate output of the next step).
- Prediction and ranking model: gets top-n recommendations-based on the following inputs:
- The sequence of browsed hotels
- Embeddings of the browsed hotels
- Rating tokens of the browsed hotels
- Realisation tokens of the browsed hotels
- What was the candidate list of hotels? High-rated hotels?
Embedding Gen
- Explicit feedback requires effort from the customers; hence, ratings are sparse.
- Browsing data as user’s implicit feedback; thus, no sparsity.
- In this work, implicit features were derived using an RNN.
- Embeddings were the intermediate output of the model training process.
Prediction and Ranking Model
- Objective: realised bookings (conversion along with the realization of bookings)
- Implemented the following four methods: RNN, GRU, LSTM, and BiLSTM.
- Training data:
- 1 million users
- Sequences of their clicked hotels within a session
- Pre-processing: padded and limited to 15 hotels.
- Model objective: the probability of the user for realised booking at high-rated hotels.
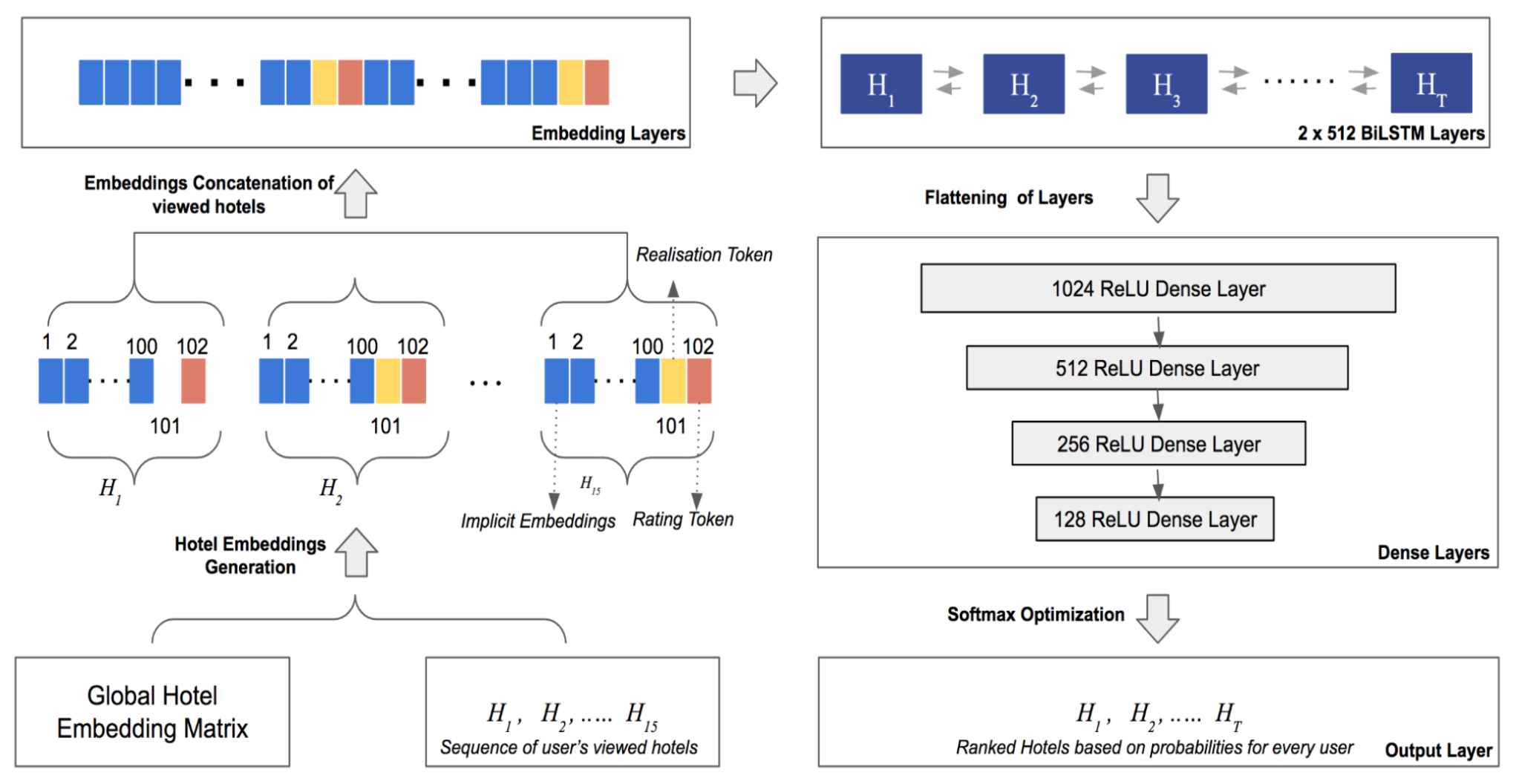
- Proposed architecture (disclaimer: I couldn’t grok it from the paper)
-
Embedding layer: 100 dim
torch.nn.Embedding(num_embeddings=all_hotels, embedding_dim=100) - Embedding concat layer (
torch.cat())- Not sure why they concatenated the embeddings.. The embedding tensor should have been input to the RNN layer. Otherwise, no recurrence will happen.
-
2 BiLSTM layers
torch.nn.LSTM( input_size=1530, hidden_size=512, num_layers=2, bidirectional=True) ) - Flatten layer (
torch.nn.Flatten()) -
4 ReLU dense layers
l1 = torch.nn.ReLU(torch.nn.Linear(512*2, 512)) l2 = torch.nn.ReLU(torch.nn.Linear(512, 256)) l3 = torch.nn.ReLU(torch.nn.Linear(256, 128)) l4 = torch.nn.ReLU(torch.nn.Linear(128, 1)) - Softmax layer
- Output layer
-
Embedding Evaluation
- Embedding dimension: 100
- Get the top 10 similar hotels for all the hotels in the training dataset using cosine similarity.
- Four accuracy metrics:
- Location
- Distance
- Price
- Ratings
-
Metric formulation
\[\text{Sim Index @ x} = \frac{\sum_{i=1}^{H} \text{sim@x}(\text{top-10 hotels}, i)}{H} \\\]- \(x\) can be any of the following: Location, Distance, Price, Ratings
- \(H\) is a set of all query hotels;
- \(\text{sim@x}(\text{top-10 hotels}, i)\) is the similarity score for metric \(x\).
- Ranges between 0 and 10.
- \(\text{sim@Location}\): fraction of top-10 hotels lying in the same city as the query hotel \(i\).
- \(\text{sim@Distance}\): fraction of top-10 hotels that are within a 20km radius of the query hotel \(i\).
- \(\text{sim@Price}\): fraction of top-10 hotels that are within +/-15% of the price of the query hotel \(i\).
- \(\text{sim@Ratings}\): fraction of top-10 hotels that are +/-1 rating from the query hotel \(i\).
- Following are the evaluation results with the winner highlighted:
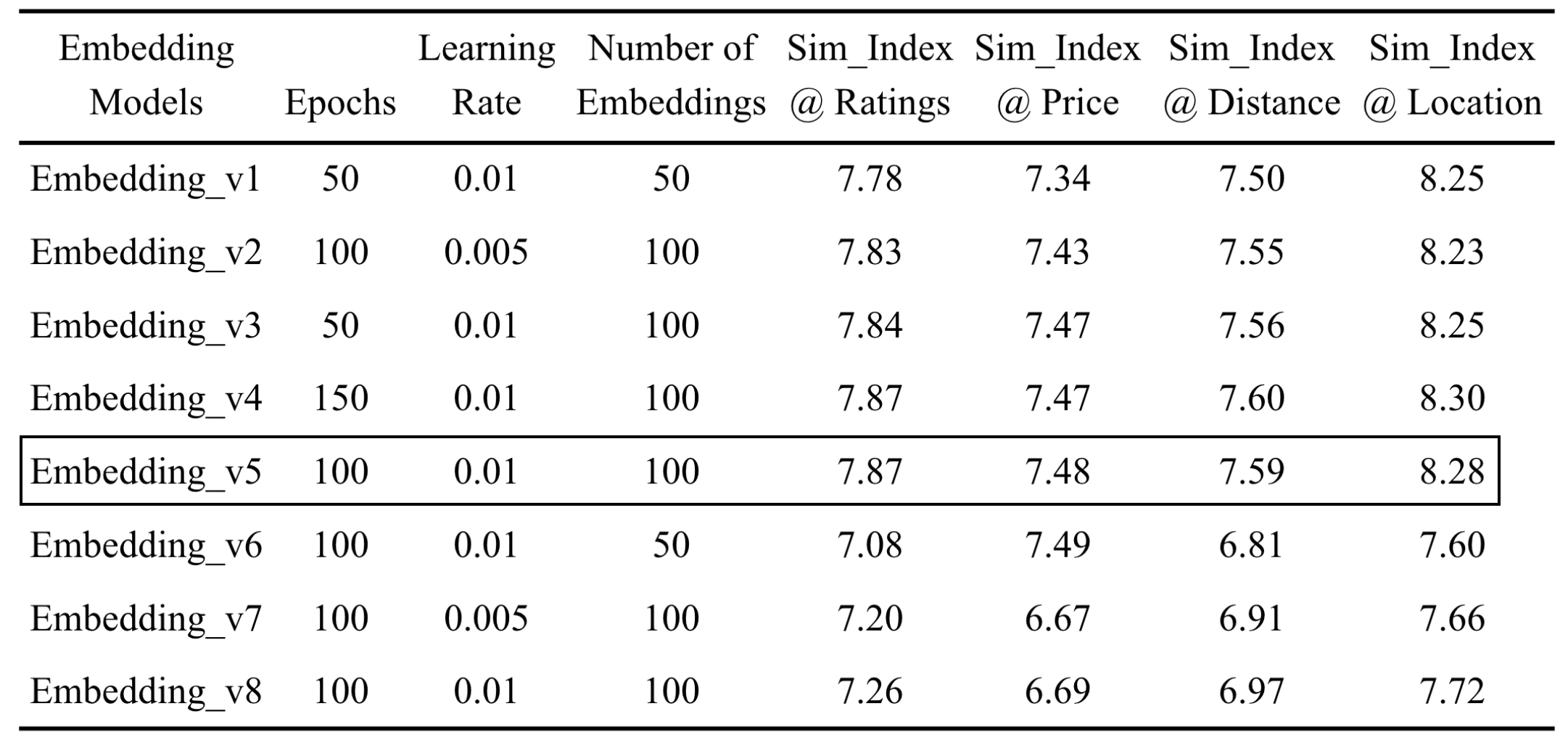
- Qualitative eval also yielded positive results.
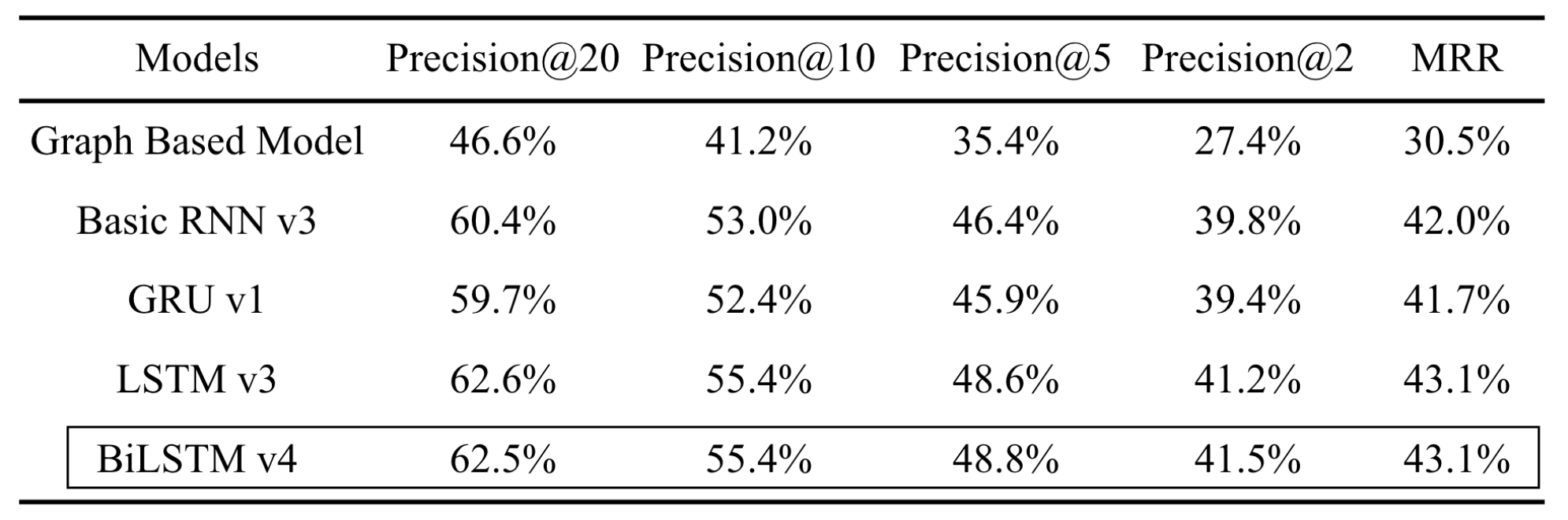
Ranking Model Evaluation
- Offline evaluation metric: Hit Ratio, MRR
-
\(\text{Precision@k}\) or Hit Ratio: fraction of users for which the booked hotel was among the top-k recommendations.
\[\text{Precision@k} = \frac{U_{hit}^k}{U_{all}}\] - 15 total model variants:
- 3 variants with basic RNN
- 4 variants each with LSTM, GRU, and BiLSTM
- Selected one variant from each model type-based on validation results.
- Created a dataset aligned with the real-time environment. (Session logs?)
- Out-of-time validation on this dataset.
- The BiLSTM variant was the best-performing model.
- Online evaluation metrics:
- Realized bookings at high-rated hotels.
- C*R (multiplication of booking conversion and realization of bookings) at high-rated hotels.
- Observed lifts of 3% to 6% in realized hotel bookings across different geographies.
Review Conclusion
- The paper proposed building a DL model with two parts: embedding gen and ranking model.
- The embeddings are the intermediate output of the ranking model. Not sure why it is called a separate model in the paper.
- The model is an important part of this paper, yet
- It does not discuss the training data construction in detail.
- Few left-out details about the architecture made it difficult to comprehend it.
- There was no discussion about inferencing and the candidate set of restaurants to rank.
- The embedding evaluation framework was comprehensive and quantified the effectiveness of the embeddings.
- Model evaluation methodology followed the standard process of train-time validation and out-of-time validation steps.
- One thing lacking was comparison with tree-based models like gradient boosted trees which have shown good performance in recommendation tasks in both industry and research.