(Mis)adventures of Building a Chat Bot
In a Telegram group of three, a fourth member was added - GB - a Telegram bot. GB is the most useless, unavailing and noisy bot there is, but it’s fun. I started working on it because, I have always been interested in building chat bots, but never had the chance. Secondly, and this is a rather ambitious thinking, I want to build a NLP system able to understand and act on the natural language. Lastly, this was more of a realization when I started my work on GB, opportunity to build NLP tools and techniques for Hindi+English (or Hinglish). In the process, I’ll be working on both basic NLP and some advanced NLP techniques. And, I’ll try to implement everything from scratch.
Note: Since our colloquial language in chats is transliterated Hindi + English, GB’s commands are also desi (read - Hinglish and Transliteration). GB’s code is also laden with desi variable, function, class, and file names. I’ll explain what the terms mean whenever I’ll use them.
I have been working on-off on this bot for the past 3-4 months now (243 commits). I have the basic structure ready. This post will discuss all the things GB has till now.
The echo function is the “Hello World” code for bots. Whatever anyone says, it’ll repeat that verbatim. This was the first commit on GB. The night before, we were discussing what commands should be present. Telegram bot API provides a command interface for the bots - a command is a word starting with “/” - and it’s easy to setup those. After echo testing, I added some of the commands discussed - /random, /yaaddila, /yaadkar, /bhulja, /gaali, /ashleellaundakaun.
Commands
Random
All the group members know each other since college. And, each of us had been a part of some embarrassing situation where one said or did something silly and others made fun of him. This leg pulling still continues. We have prepared a list of such statements and whenever we use /random (now called, /r) we are presented a random incident and reminding us the incident. We often use it to roast each other.
Yaaddila, Yaadkar, Bhulja
These, IMO are the most practical commands in GB. Sadly they are rarely used now. Their meanings are - remind me, keep this in mind, forget about it - respectively. Whenever there are some important bits that we don’t want to remember, but occasionally feel the need to use, we add it using /yaadkar. Information like, our server IP, our Blog links, etc is currently added here. Using /yaaddila, we can retrieve that info by giving the key. And, if the information is not needed anymore, /bhulja is used. All the key-value pairs are saved in a JSON file. The commands were later shortened to - /yd, /yk, /bj.
Gaali
This is one of the most entertaining command. Even though it just adds noise in the group, it’s usage is generally chucklesome. Gaali in Hindi means a cuss word. When you command GB using /gaali it selects a random expletive. If you use /gaali <username>, GB cusses at that user. This is the basic usage. The command was later changed to /g.
To give GB a Swearing-101, I first created a list of the usual dirty phrases that my friends use. It got repetitive after some time, so I found a bigger, open-source list - Our List of Dirty, Naughty, Obscene, and Otherwise Bad Words. I took Hindi and English ones. It was not repetitive anymore, but there were many words in that list which are generally bad, but do not make sense in our context. Consequently, sometimes the random gaali that GB replied with, did not make sense at all. At times it was funny - the dumbness of the bot, not the usage of the wrong gaali - but usually, it denied us the hilarity that would have come if the right abuse had come. So, we culled the list; added some more forms of the hindi abuses. Now the results were better. My friends occasionally bring/invent new phrases, so this list keeps getting longer.
There is also one easter egg in the /g. If someone tries to use /g to abuse itself (using /g GB) then GB retaliates by abusing the user himself.
Unsolved Problem 1: There is still one hiccup with the current list. This list contains various forms of abuses - singular, plural, masculine, feminine,
Unsolved Problem 2: Some words can be both - expletives and non-expletives.. Currently, every use will be counted as a bad word, which is wrong. For ex. the Do Androids Dream of Electric Sheep? author’s name - Philip K. Dick - contains the word dick, which we all know is a bad word. In the current scenario, using the name will increase the count, but it should be counted.
Ashleellaundakaun (Ashleel laund(i)a kaun)
Who is the dirtiest guy? That is what ashleel laund(i)a kaun means. GB constantly monitors the chats and maintains a count of expletives used by each user which we can retrieve using /ashleellaundakaun (later renamed to /a). It’ll also use @mention to mark the topper so that a notification goes to that user specifically.
This part was somewhat challenging, mostly because of a lot of edge cases. The basic implementation was just an exact string match of the reply in the vocabulary. I’ll list the edge cases and their solutions-
- Limited vocab. So not every cuss word was being counted - inserted the vocabulary of dirty words from the Github repo to make a master list. Initially this list and the list used in the /gaali command were different, later, they were combined.
- Profanities could be mid-sentence - split the reply into words and then check in the list.
- Multiple word abuses - prepare bi-grams and tri-grams from the reply and then check each one in the master list.
- Single word abuses split into multiple words - elide the n-grams (n goes from 1 to the number of words in the reply) into single words and then check against the master list. Eg. “mother bugger” to “motherbugger”
- Making a cuss word unnecessarily long by repeating the characters - reducing the repeating characters into a single character. Eg. “shiiiiiiitt” to “shit”.
- Using accented characters in an abuse - normalizing the characters to ascii characters. Eg. “shít” to “shit”
- Using Devanagari (raw Hindi) instead of transliterated Hindi. Gboard provides keyboard for Indic languages which enables you to write in transliterated Hindi and it’ll give you the Devanagari version. (Did I mention that my friends are good at finding workarounds?) - Here we made an elementary transliteration engine (a bit better than elementary). Detect whether the word in the reply is written in Devanagari, if yes, then transliterate it to get top 10 transliterations and check if anyone of those is in our master list.
- Wrongly spelled abuse - while building the spelling corrector (will discuss in the next section), added the part that, if a corrected word was in the master list then increase the count for that user.
After this much work on this one command, one friend exclaimed -
This must be the most exhaustive gaali detector for hinglish ever made.
While working on the transliteration bit, I got to know a few things about the world of transliteration and specifically, about Hindi transliteration.
- There is not a single transliteration. Colloquially, there are multiple transliteration versions in use.
- There are standards of transliteration systems which try to give unambiguous transliterations, but it’s still challenging because some sounds are not present in the English so they have to use dots or capital and small alphabets.
- Transliteration can be between any two language scripts. Transliteration to English is called Romanization. So here we are talking about Devanagari Romanization.
- There is not much present - both research and data - on the transliteration of Hindi into English. There are one or two labs where some research activities are being done on Hindi language, but not sure if transliteration is a part of their research.
- Google has a deprecated API (but still functional) which returns top n transliterations (or all, if parameter given).
- There are some ways of training neural network models to get a transliteration engine. But they need labeled data to train. Which is hard to get by. However, in a recent research by Amazon Alexa researchers working on named-entity transliteration, the training data was found in Wikipedia data. They took advantage of the fact that a person’s wiki page usually contains their name in multiple languages. Thus, they have a mapping from between 2 scripts. They didn’t do it on Hindi though.
We’ll come back to transliteration.
Spelling Correction
We all know what spelling correction is. It’s usual to make a few typos in a conversation. So, I had the brilliant idea of building one from scratch. Since, it’ll be for Hinglish and not just for English, I thought, it’d be fun. Let me tell you how fun it was.
I only knew about the dictionary based spelling correctors. You’ll have a dictionary of possible words, against which, you’ll check a given word. If it’s there then good otherwise you have just caught a wrong spelling. Now you have to correct it. Correction can be done using a string similarity metric. I don’t like this approach though. So, I googled how to build one. The first result was a toy Spelling Corrector written by Peter Norvig. I had seen this post before, but somehow, I didn’t remember the details (no wonder I felt the need for /yaaddila command in GB). The best part of the post was that he had presented it in just 36 lines of code achieving around 70-75% accuracy. I integrated it within GB.
For GB’s correction engine, I used the biggest file Dr. Norvig had used in his toy corrector. This was just the English data - around 6.2 MB in size. To correct Hindi spellings, I needed transliterated Hindi data. I had a lot of Hinglish data lying around from my FB/WP chats. Additionally, I asked my friends to give me some more. There was around 4 MB of Hinglish data in total. So I had 2 language text sources - english.txt and hindi.txt. And, I made the system live. lol.
Flaws
I was very fortunate that my friends didn’t kick me and GB out of the group. How ironical is this, the thing that is supposed to correct your mistakes is making mistakes more than you. On some of the obvious cases it worked as intended, but on the others, it failed miserably. There was an incident when one of my friends got so annoyed that he cussed at GB and GB in return corrected the cuss-word into something ridiculous. With daily usage, we started seeing the flaws in the correction engine.
-
Small Vocabulary: We were lacking in both English & Hindi data. For example, our discussions on group largely revolve around computer science and technology. And, GB constantly faltered on such CS related words. Examples -
hosting -> costing browser -> brother corrector -> correct dedup -> deep dict -> duct concat -> coat linux -> line notification -> ratification So I added a few Wikipedia pages on CS topics - Data Structures and algorithms, Machine learning related pages, etc. I also added a few wiki pages having information about India - Indian sub-continent, Indian governmental bodies, Indian dishes, etc.
Since this vocabulary enhancement was going to be a recurring activity, I picked Wikipedia as my base source. Whenever there was some English mistake by GB, I looked for that page or the page containing that word and add it in the base file. This had a few advantages
- I got different forms of the same word;
- I also got other new words;
- I got sentences where this word is in use (this will help in n-grams based approach discussed later)
For Hindi, I tried to find some blog post having that word and added that to the
hindi.txt. Otherwise, it went to a new filenewvocab.txt.Manually adding the vocabulary was a drag. Find the wiki page, copy the content to the
englist.txt, recalculate the word frequencies and then restart the bot. So I made a command -/new, which when given a keyword, searches for the keyword on Wikipedia, if found, adds the vocab to the the base file and then recalculates and reloads the frequency counts for the bot. If word was not found on wiki, added the words to thenewvocab.txtand reloaded the freq counts. This made things easy for me.To take it a step further, now, whenever GB gives a correction for something, it also gives 3 buttons along with it. With the help of this feedback, I am also able to collect the corrector evaluation data.
- Thumbs up means the correction is right;
- Plus means the correction is wrong because the word is not in it’s vocabulary and adds it to the
newvocab.txt; - Thumbs down means the correction is completely wrong and word is also wrong so it should not be added to the vocab as well.
-
Nonsensical Corrections: The
english.txthave some Sherlock Holmes stories and some Shakespeare plays too. There were many names, some classical English words. Inhindi.txt, there was long tail of words with frequency 1, many of which were wrong spellings or rarely used Hindi words. All these infrequently used words and names and wrong words, get mixed with the words (both new and wrongly spelled) used during the conversation and gave a lot of nonsensical corrections. For eg-- paagal -> paagl (Hindi for crazy; paagal is correct; paagl is nonsense)
- tminima -> minims (tminima is my username on Telegram; don’t know what minims is)
- raspbot -> rasbt (no idea what rasbt is)
- thissss -> issss (should have been corrected to this; issss is nonsense)
- fneoe -> fnese (both words are nonsense)
The solution to this was filtering out the frequency 1 words from the vocabulary. This worked better than I had expected.
-
Sanitization and Tokenization: Due to a very basic text sanitization (stripping of white spaces and special characters) and tokenization (simple split on spaces and other punctuation) there were many unwanted corrections.
-
It corrected parts of urls. eg. in https://github.com/dwyl/english-words it corrected dwyl to dwy. This was a nonsensical correction of an url. Incredible. Added a regex to remove urls from the text. Similarly a regex based filtering was done for the emails, reddit subs, twitter handles and hashtags.
-
It corrected strings like hahahahahah to the closest match. Added regexes for such common strings - looooool, dayyyyyyum, etc - to replace them with a standard version. In this case replaces hahahahahah by haha.
-
Corrections for the numbers and words starting or ending with numbers. Example, it corrected 3C2 (Permutation and Combination notation for choosing 2 out of 3) to 32. Removed all numbers and words with numbers in them from the vocabulary.
-
-
Morphology: Due to the absence of different forms of some words, they got corrected to the form that was present in the language model. Eg -
standardised -> standardized phonetics -> phonetic conversions -> conversion generated -> generate For now, I have handled this in a very hacky way. For each correction and original word pair, I remove the suffix (from a list of suffices) and then check if they are same thus rejecting the correction. This way of handling the morphology is very fragile. I had to handle the possessive/non-possessive forms differently. I’d like to work on this more in future.
Unsolved Problem 3: It is not able to correct the word which exists in the vocabulary, but its usage was incorrect. Ex. in the following sentence, you know shell be fine, every word is correct if you look at the spellings, but usage of shell is wrong. It should be you know she’ll be fine. In another example, the ONLY issue is, ki word cound ka indication kaise hoga!, “cound” is wrong word and doesn’t exist in the vocabulary, but GB corrected it to could instead of count. This indicates that context is important for us. Dr. Norvig placed a very high trust in context based approach. He discusses a n-gram based approach to use context. I am yet to implement it, but it should solve this problem.
Unsolved Problem 4: The error model in the spelling corrector is pretty basic - select which is most probable in the valid words with edit distance 1; if there are no valid words then move to the words with edit distance 2; if there’s no such words then do not correct it. Here first preference is given to the words with edit distance 1 even if the correct spelling is in the words with edit distance 2. Correction to be given is using this error model. For ex. have a look at the following cases-
-
Wrong spelling: reciet Actual spelling: receipt GB’s spelling: recite
-
Wrong spelling: adres Actual spelling: address GB’s spelling: acres
-
Wrong spelling: yeau Actual spelling: yeah GB’s spelling: year
-
Wrong spelling: usje Actual spelling: uske (“uske” means “his”) GB’s spelling: use
In the case of adres, the error model can be updated such that the two edits of “d” to “dd” and “s” to “ss” should have high probability than the single edit of “d” to “c”.
The error model can be updated by taking into account the layout of qwerty keyboard. In the case of yeau, “h” is closer to “u” then “r” is to “u” and thus the change from “h” to “u” should have high probability. Similarly, in usje, “k” is adjacent to “j” so it should be given higher probability than the deletion of “k”. I’ll look into this, once I have implemented the n-grams based approach.
Unsolved Problem 5: It’s not able to handle contractions properly. Basically, I want to correct cant to can’t, hes to he’s and so on. The tokenizer extracts these words from the base data, but the error model doesn’t give the right results. I haven’t investigated the results in deep yet, but I am hoping, it should be solved by n-grams. Other way can be, there is a fixed list of contractions, so each of them can be individually matched and corrected.
Implementation Challenge
My workflow while working on GB is to code and test it on my personal laptop and then push it to server for deployment. Now there’s a major difference between the 2 machines - my device has 8 GB RAM, 12 GB Swap, 4 cores and the server has 512 MB RAM, 216 MB Swap, 2 cores. I am not getting into the reasons, but I had to make do with this.
Initially, for the spelling correction, the english.txt and hindi.txt were processed every time the bot started, frequencies were calculated and then it was ready to make corrections. When the new vocabulary started adding up this process got slow and consumed more memory. I was okay with this as it was done only once during the bot startup. One day, data increased to the limit that the kernel killed the process during the launch. That day I learned, the linux kernel kills a process if it does not have enough resources for it.
I checked the data file, it was hardly 30-40 MB in total. Loading it should not make the server go out of resources. I was keeping all the loaded data in the global scope. I defined counter prep function which returns the prepared counter only. Thus deleting all the data loaded automatically when the function ended. Then, I made the process iterative. So that it reads, processes and updates the counter, one line at a time. This made things better.
To make the process more efficient, I pickled the prepared counter and whenever bot restarted just loaded that. This eliminated the data processing on every bot startup. And this worked very smoothly. It only had one flaw - whenever the vocabulary was updated I had to restart the bot to make the new vocabulary come into effect.
For updated vocabulary to take effect without restarting the bot, I made a class and added vocabulary update methods. At a time, there’s only a single object of this class in the memory. So whenever a new Wikipedia page was added, it added the text to the english.txt and also updated the counter currently in the memory and updated the saved pickle. So, all the updates are iterative now, improving the vocabulary and bringing it into effect at the same time without restarting the bot.
Unsolved Problem 6: Even now, it loads the prepared counter in the memory. As the size will increase, it’ll take more time. I haven’t yet thought about how to work through this issue - make it use less memory. Although, it’ll take time to reach that size. So this issue has taken a back seat.
Data
Lets talk about data. If you read the previous section on spelling correction, then you would know, we need more data, and particularly, more Hindi (or Hinglish) data. So that we have a good Hindi vocabulary along with good English vocabulary. Most of the wrong Hindi corrections are because of the absence of that word from the GB’s vocabulary.
Towards this vocabulary building goal, here is the list of sources I have included till now;
-
All the articles of this blog - memsahibinindia. It’s mostly written in English, but the author talks a lot about India and describes the dishes and places of India. She also uses Hindi words at times.
-
All the articles of this blog - blogs.transparent.com/hindi. This blog aims at explaining Hindi words in English by using them in a narrative. It will first list the English translation of the word followed by writing it in Devanagari, and within brackets, the transliterated version of the it. Since the target audience is the Hindi learners, it tries to introduce many new Hindi words, in effect, giving us more Hindi vocabulary.
-
Hindi song titles and lyrics. I googled for some Hindi song titles and lyrics dump. Found a few, but they were all transliterated using some transliteration standard which was not same as our usual transliteration. So word tokenization would have given some unwanted words. Filtering on this basis, I was only left with one dump and added it in the
hindi.txt. -
Scraping the comic headlines and the panel text from Amul comic panels. Amul is one of the biggest milk supplier in India and almost daily they release a comic in the newspaper where they take the headline or some major event and turns it into a pun using their products. A lot of it is in Hinglish. Recently, I stumbled upon the page where they have all these captions and comics digitized. I scraped all the puns and ingested it into GB’s vocabulary.
Unsolved Problem 7: Twitter is another source of Hinglish data, but to sift through all the tweets to look for Hinglish ones is drudgery. I thought of an approach where I get all the tweets of all the Indian comedians active on Twitter. They occasionally tweet in Hindi. Other than that, I also observed that when some new movie comes, many users tweet in Hindi using that movie’s hashtag. Getting all the tweets under those hashtags is another way of getting the data. I haven’t started working on this yet.
Unsolved Problem 8: I didn’t get an exhaustive list of all the Hindi songs - the titles as well as the lyrics. There are some websites having this data. I need to code a scraper to acquire all this information. Since there are A LOT of songs to scrape, this scraper will take some time to code.
Unsolved Problem 9: Lets come back to the transliteration. A good Hindi to English transliteration engine can also help us acquiring more data. It’ll give us more Hindi data for spelling correction (and other NLP things). This is not very high on the priority list. A few ways of attacking at the problem:
- Build a similar dataset like the Alexa researchers from Wikipedia for the names and build a transliteration model on it.
- Instead of just using the person names, also take other concepts like fruits, vegetables, places and other item/topic pages, and then train some translation or sequence-to-sequence model on it.
- Create a list of words written in Devanagari from Hindi Wikipedia or other sources from the web and then for each word, using the Google’s deprecated API, get all the transliterations for that word. Then create some kind of scoring function to trim that list of transliterations and then transliterate the Hindi literature using these base transliterations.
Unsolved Problem 10: Scoring mechanism to reduce the number of transliterations. Google’s API or our own code or any other model, all would (and probably should) give a set of possible transliterations for a Hindi word. So we’ll need some scoring metric to only keep the most plausible ones among the possible transliterations, or to reduce the list to a top 1 or 2 suggestions. One approach, I have for this, is to build a Markov Chain from the current Hindi data and then determine the path score of each possible transliteration and then select the top 1 or 2. I have no idea how good of a scoring metric this is.
Logging
Up until August, there was no logging present in GB. Only text/JSON files maintaining the basic data required. Then I integrated sqlite with GB. Designed the table structure. Created the CHATS table. Schema has a lot of things -
- Message sent (string);
- Person who sent the message (string);
- Group name or the individual name if it’s a personal chat (string);
- Was it a command (0 or 1);
- Was this a reply from the bot (0 or 1);
- Was this message quoting another message (0 or 1);
- What’s the quoted message (string);
- Number of links in the message (integer)
- What are the links (string);
- How many gaaliya (abuses) were there (integer);
- What gaaliya were mentioned in the message (string);
- How many corrections did GB suggest (integer);
- What were those corrections (string);
- Vocabulary counts whenever
/newis used - total words, new words added, total unique words (integers); - Code switching positions - not being used currently (string);
- Raw json of the message sent by Telegram API (json string).
Obviously, other fields will be added as new features will be introduced. For ex., I am not logging the feedback sent using the buttons on the spelling corrections made by the GB.
Additionally, CHATS table is not even in the first normal form (or 1NF). The gaaliya, links, and corrections fields have pipe separated strings. To get the individual elements of the list, I have to split by pipe in code. Thus the atomicity property is not fulfilled. As the size will increase, I might think about normalizing it. Currently it’s not needed.
Weekly Stats
I have added a few stats which are displayed weekly. There is one for each day. Logging of the chats made things straightforward to query for these stats.
Gaaliya
Every Monday, it lists the abuses each person gave during the last week. It also tags, using the @mention, the one with the highest count.
Now when this gaali counting started, we all were very active in profanity (of course, me being the least active). Now, two out of three members (2 friends and I) of the group, have almost completely stopped using such language in the group. We now use other hints and innuendos which everyone gets. For ex. now whenever we want to use some bad word, we use /g in it’s place. And everyone gets it. This usage to me is really amazing. How some man made construct is used naturally in our conversations and everyone understands the meaning associated. Anyway, the third guy who still cusses a lot (although, it’s lesser now) is more-or-less consistent with his abuse counts. I’d like to believe that this weekly notification helped us decrease our use of such language. :D
Wordcloud
Every Tuesday, we get a wordcloud from the messages of the last 4 weeks. This required a bit of work. I had to build a Hinglish stopword list to remove unwanted words from the wordcloud.

Links
This lists, every Wednesday, the number of links shared by each person during the last week. I don’t know, how is this useful. I just implemented it.
Corrections
This lists, every Thursday, the number of corrections GB made for each person in the last week. This might help in measuring whether GB helped reduce the mistakes in the group. Or putting it in other way, how effective is GB in helping us achieve a certain efficiency or improvement. Not that we care about this quantification, but I am just giving an example of what can be done.
Commands
Every Friday, we get the number of commands given by each person to GB during the last week. The use of commands has declined now according to these weekly stats. Rarely does anyone interacts with GB using commands. Mostly /g is used now.
I think, using commands ought to be like this. Commands are sort of prohibitive. You need to learn what each command does. You have to be specific with the arguments while using the command. It is close to the texting culture but does not feel like an integral part of the culture. For example, for wrong corrections, GB has both, /new command and the feedback buttons. But even amongst the three of us, only I used the /new. Whereas, the feedback buttons have somewhat blended with the normal flow of the conversation and we all use it whenever they pop up.
Quotes
Every Saturday, it lists the times how much one person quoted another. You can see how it is done currently.
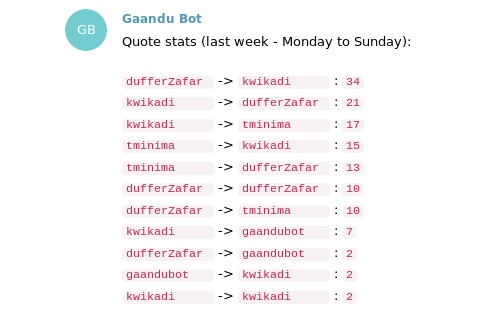
When I had thought about this, I was imagining a graph, like D3 force graph. I am yet to work on this part.
Messages
Every Sunday, we get the user wise counts of messages we have sent on the group in the last week. GB is also included in the list of users.
Conclusion
I have the basic infrastructure ready for the bot. I have a database which logs everything being spoken on the group. I have built a fairly decent spelling correction. There are many other improvements in the pipeline to be done. There are some interesting problems to solve. And, I think, this is just scratching the surface.
There are a lot more advanced things which I’ll be working on now. Sentiment Analysis, Entity Recognition, NLP, Deep Learning, Knowledge Graph and other interesting stuff. I have given a cursory attempt on training a word representation model (Word2vec) on the Hindi data. Didn’t work that well. Also tried an LSTM to make the bot say something on it’s own. It also failed. Will give these another go after getting a better understanding.
While working on this project, I also delved on a more philosophical topic. How can these chat bots be used effectively? We started off with GB to get some useless features to make the group fun. But now, whenever, I think of making it useful to us, I cant think of anything amazing to implement. Sure there is that command interface which we can use to make it do anything in our power to code. We can also ask it to monitor some processes running on a machine. We can make it track some events - conferences, hackathons, etc. We can also ask it control some IoT devices. But are these functionalities making things effective for us or are they just the replacement of the old/traditional ways? Having this bot available on our smartphones helps. But are we using this enhanced accessibility to our advantage?
I am also conflicted about how a bot should function. A command based interface where everything is to be predefined or a more blended interface where it just works whenever it’s needed without explicitly calling it. Latter one seems more natural, but then it strips away control from the users. Former path seems prohibitive. May be, having both - a command interface and non-command interface - will feel better and blend better. I have mostly worked on the command interface till now. Going forward, I’ll experiment with some non-command based functionality.
I believe that an intelligent system can properly be made with the combination of Natural Language Processing (NLP) and Reinforcement Learning (RL). I have zero idea of how RL works, but I think, if I am able to improve a model using the feedback it receives, then I am employing RL. In normal RL systems there’s an objective function as a goal here we don’t have any such goal except working satisfactorily to get a positive feedback from the user. I’ll also focus on having such systems in place and iteratively making the models better in GB.