Jekyll2026-03-08T11:29:02+00:00https://trigonaminima.github.io/feed.xmlPlaygroundShivam RanaMove US Stocks from INDMoney to Interactive Brokers2026-03-08T00:00:00+00:002026-03-08T00:00:00+00:00https://trigonaminima.github.io/2026/03/indmoney-to-ibkrI wanted to move my US stocks (securities) from INDMoney to Interactive Brokers. I didn’t find any clear steps documented anywhere. It took me multiple attempts to finally be able to move over my portfolio.
This post is divided into two parts: steps followed and FAQs.
Steps
Absolute Pre-requisites
Have an active account on IBKR. That means account verified and ready to buy stocks.
Make your fractional shares whole on INDMoney. That means either going from 1.6 qty to 1 qty or 2 qtys.
Keep at least USD 70 in the INDMoney wallet.
Now, here are the steps to transfer:
Log into IBKR.
In the menu, go to Tansfers (Deposit, Withdraw and Transfer History) (or whatever they are calling it now).
Go to Transfer Positions.
Select Incoming
Select region as United States as DriveWealth, the broker used by INDMoney, is in US.
Select ACATS as the transfer method. (usually the very first option and the most convenient)
Choose DriveWealth in the broker dropdown.
My account number looked like: IFSC-XXX-<Account number on the INDMoney app> (17 characters). Account number is the crucial part. One of my requests failed becuase of this. INDMoney doesn’t make it easy to find your account number. DON’T use the one shown on the app. Follow: US Stocks Tab → Manage → US Stocks Reports → US Trades Report to find your account numner.
Account Title and Tax Identification Number are pre-selected. Choose your Account Type. Mine was Individual.
Decide FULL ACATS or PARTIAL ACATS transfer. I did FULL ACATS. You can’t have any fractional shares for full transfer. Refer FAQs for more details.
Give authorisation to IBKR to take appropriate actions when the positions of you are transferring are not the products IBKR supports. IBKR has given details on what you are giving them the authorisation for. I selected Yes for everything.
Verify your details. Sign and submit.
IBKR will validate and confirm the request, submit it to the DriveWealth, receive the stocks. You will get an email from IBKR about the completion or failure.
FAQs
Q: What are the tax implications of the transfer process? A: My research told me that transferring stocks incurs no capital gains tax, as it’s a dealer transfer, not a sale. Verify with your CA. Notwithstanding, maintain your transaction records with the earlier platform for tax filing purposes.
Q: Who is INDMoney’s broker? A: DriveWealth
Q: Region to select for the transfer. A: DriveWealth is a US broker. So region is United States of America.
Q: What is incoming ACATS and outgoing ACATS? A: Since I wanted to get the securities out of DriveWealth, it is going to be an outgoing ACATS for DriveWealth and incoming ACATS for Interactive Brokers.
Q: Who initiates the ACATS (Automated Customer Account Transfer Service) transfer request? A: Always the receiving broker. So, there is no need to interact with INDMoney unless there is some snag in the process and you need help.
Q: Is DriveWealth (INDMoney’s underlying broker) ACATS transfer enabled? A: Yes, I confirmed this with INDMoney.
Q: Does DriveWealth charge a fee for the (outbound) transfer? A: Yes, I was charged USD 65. I confirmed this with an INDMoney customer support request. Their explanation:
For outgoing ACATS transfers, a fee is typically applied by your U.S. broker. This charge is levied by the broker currently holding your assets to facilitate the transfer out of their system.
Q: How do I pay for the DriveWealth fee? A: Keep at least USD 70 in the INDMoney wallet.
Q: Does IBKR charge a fee for the (inbound) transfer? A: I was not charged anything.
Q: Is there a penalty for transfer failures due to any errors? A: I was not charged anything. I successfully transfer in my third attempt.
Q: How long does it take to complete the transfer after submission. A: It took 4 working days from submission to completion for me. Under standard conditions, ACATS transfers to IBKR complete in about 4–8 business days after submission.
Gemini says that some industry sources note 3–5 business days in smooth cases.
Q: Can I trade on INDMoney during my transfer process? A: I avoided it after I raised my transfer request. INDMoney’s response:
During the outgoing ACATS transfer, trading activity (including deposits, buys, and sells) will be temporarily restricted to ensure the process completes without errors.
Q: Can I trade on IBKR during my transfer process? A: Yes.
Q: How does it work if the residency status has changed - INDMoney app having residency A and IBKR having residency B? A: Many people on this reddit thread seemed to think so. I tried, and it worked for me.
Q: My address is different on INDMoney and IBKR. Will it work? A: It worked for me. According to Gemini, the ACATS system relies on an exact match of key identifying information between the delivering account (INDmoney’s partner broker) and the receiving account (IBKR) to prevent unauthorized transfers. The key matching criteria is:
Account Title/Registration: Your name must be identical on both accounts.
Account Type: (e.g., Individual, Joint, etc.) must match.
Tax ID: (e.g., Social Security Number, or other tax identification used) must match.
All three were supplied by me. So, I guess that’s enough. I think it would have mattered if my country of residence had been US, because then my Tax ID would have changed.
Q: How do I track my transfer? A: INDMoney doesn’t tell you anything about the transfer or the status. You will not even get a notification/email after the transfer is complete. Only place to track the transfer is on IBKR. Follow the same steps that you followed to initiate the transfer. IBKR will guide to the the status window.
Q: How are fractional shares handled? A: This caused a lot of research for me. Everyone online mentioned that you can’t transfer fractional shares. INDMoney also confirmed this:
Please note that fractional shares cannot be transferred. These may be liquidated as part of the transfer process.
So this was clear. What was not clear was: do I need to make them whole or will it only transfer the complete units and leave the fractional units in INDMoney? The latter part of INDMoney’s response gave the impression that it will handle the liquidation on it’s own. This assumption was incorrect. My request was rejected because of fractional shares.
So, as I mentioned in the pre-requisites, make your fractional shares whole or exit entirely. That is, turn 3.55 units of NVDA into 3 or 4 or 0 units or NVDA.
Q: Can I use partial transfer to avoid selling my fractional shares? A: I was always trying for full transfer. When the request was rejected due to fractional shares, I contemplated using partial transfer to avoid exiting. I was avoiding selling for two reasons:
I wasn’t sure if selling would lead to any tax implications;
Some of my stocks were bought at very attractive prices. I want to protect my avg price.
After some thought, I decided to make them whole. Exited some of the fractional shares and bought some of the others (when there was a dip).
Q: Does the ACATS transfer also take care of transfering my buy/sell history, avg price and other associated history? A: Not sure what is supposed to be transfered. What I got was only my avg price. All the past buy-sell history was gone. Since it was gone, my CAGR type metrics were also gone.
Q: What resources did you refer to understand the process? A: Here are some links
]]>Shivam RanaPyTorch Fundamentals - Week 52025-11-29T00:00:00+00:002025-11-29T00:00:00+00:00https://trigonaminima.github.io/2025/11/pytorch-fundamentals3Brushing up on my PyTorch skills every week. Starting from scratch. Not in a hurry. The goal is to follow along TorchLeet and go up to karpathy/nanoGPT or karpathy/nanochat. Previously,
]]>Shivam RanaPyTorch Fundamentals - Week 42025-11-22T00:00:00+00:002025-11-22T00:00:00+00:00https://trigonaminima.github.io/2025/11/pytorch-fundamentals2Brushing up on my PyTorch skills every week. Starting from scratch. Not in a hurry. The goal is to follow along TorchLeet and go up to karpathy/nanoGPT or karpathy/nanochat. Previously,
Turns out, torch.where() is the most optimised way of doing this. It is vectorised and GPU-friendly. It is also a cleaner implementation of the same logic. Masking will require extra memory and extra operations (two multiplications, and one addition).
Used tensorboard to visualise the training results.
PyTorch accumulates gradients by default. The loss.backward() will add to the previous gradients (can be accessed by weight.grad).
If we don’t reset the gradients using zero_grad(), the new gradient will be a combination of the old and the newly-computed gradient. Since the old gradient was already used to update the model in the last iteration, the combined gradient will point in a different direction than the minimum (or maximum.) [ref]
Q: When should we use zero_grad()? A: When we want gradient accumulation on purponse.
Q: When do we want gradient accumulation on purpose? A: In the following scenarios:
Large batch size with limited gpu memory. Split the batch into mini-batches. Accumulate gradients for all the mini-batches and then run optimizer.step(). Used during training on smaller GPUs.
Multiple loss components before a single update. Useful for multi-task learning. Losses that require multiple passes.
Parallel training. When model is split across devices -> accumulate the gradients across the micro-batches and then update parameters once.
Training with noisy gradients. Accumulate over multiple steps with noisy gradients to smooth the gradients before updating.
]]>Shivam RanaPyTorch Fundamentals - Week 1, 2, & 32025-11-10T00:00:00+00:002025-11-10T00:00:00+00:00https://trigonaminima.github.io/2025/11/pytorch-fundamentalsBrushing up on my PyTorch skills every week. Starting from scratch. Not in a hurry. The goal is to follow along TorchLeet and go up to karpathy/nanoGPT or karpathy/nanochat. Summary of the 1st three weeks.
Week 1
Create a Linear Regression model.
torch.nn.Linear to define a learnable model.
forward() for forward pass.
model.parameters containing all the learned weights and also passed to the optimizer (SGD, Adam, etc.)
Use torch.no_grad() during inferencing.
Log the training logs to TensorBoard. (not a part of the TorchLeet repo)
SummaryWriter from torch.utils.tensorboard. Tensorflow can directly use a callback inside the fit function to push all the relevant logs. The SummaryWriter gives a fine-grained control to log anything.
add_scalar() to log the training loss.
add_graph() to log the graph itself.
Load the Jupyter tensorboard extension so that we don’t have to leave the notebook to look at the logs and and pretty plots.
%load_ext tensorboard
Load the tensorboard UI inside the notebook.
%tensorboard --logdir PATH_TO_LOG_DIR
Week 2
Create a Dataset
Dataset class from torch.utils.data.
Create a subclass of Dataset for my specific dataset. Added data, X and y attributes to the class.
Since we will iterate through the rows of this dataset, defined __len__ and __getitem__ functions. These overloaded functions enable code like len(dataset) and dataset[i], respectively.
Dataloader
Dataset only defines the dataset. Dataloader from torch.utils.data creates an iterator. It also brings other capabilities like batching and shuffling. Eg:
Trained the Linear Regression model using the dataloader. Faced some issues due to dtype mismatches - used torch.float32 everywhere to fix it.
The exercise only asked for a single column dataset. Played around with a dataset with multiple columns.
Use tensorboard for all the logging.
Week 3
Two types of activation functions – with learnable parameters and without.
Activation function with learnable parameters will require a nn.Module subclass. It is required to do the gradient calculations using forward and backward functions and get the final trained weights.
Created a custom activation without learnable parameters: \(\text{tanh}(x) + x\).
Updated the Linear Regression class to have the final output go through \(\text{tanh}(x) + x\) using torch.tanh().
returnself.custom_activation(self.linear*(x))
This SO answer talks about how to write a custom activation function in different scenarios: non-learnable, learnable, learnable with PyTorch functions, and learnable without PyTorch functions.
Also learned about torch.nn.Parameter and torch.nn.Variable.
Kept using Tensorboard for all the logging.
Next 2 weeks: Custom Loss Function (Huber Loss) and Deep Neural Network
]]>Shivam RanaLife Logging: Calls2025-09-28T00:00:00+00:002025-09-28T00:00:00+00:00https://trigonaminima.github.io/2025/09/life-logging-calls-taskerI am building a comprehensive set of tools to do life logging. General idea is:
Push everything to a sink; and
Visualise the data in this sink.
Objective is to do weekly reviews and take interventions if things are not BAU. Long term vision is to eventually have enough signals to give me a comprehensive understanding of myself (physical, mental, social, financial, etc).
Profile: Log Phone Calls
Event: Phone Idle
Enter Task: Call Logs
A1: Variable Set [
Name: %call_log_cols
To: date, geocoded_location, countryiso, type, number, name, duration
Structure Output (JSON, etc): On ]
A2: SQL Query [
Mode: URI Formatted
File: content://call_log/calls
Columns: %call_log_cols
Order By: date desc
Output Column Divider: ,
Variable Array: %call_logs
A3: Multiple Variables Set [
Names: %qs_ts, %call_geocoded_location, %call_countryiso, %call_type, %call_number, %caller_name, %call_duration
Variable Names Splitter: ,
Values: %call_logs(1)
Values Splitter: ,
Structure Output (JSON, etc): On ]
Use Global Namespace: On ]
A4: Variable Clear [
Name: %call_logs ]
A5: If [ %qs_ts neq %LAST_CALLTS ]
A15: If [ %call_type eq 1 ]
A16: Variable Set [
Name: %call_type
To: in
Structure Output (JSON, etc): On ]
A17: Else
If [ %call_type eq 2 ]
A18: Variable Set [
Name: %call_type
To: out
Structure Output (JSON, etc): On ]
A19: Else
If [ %call_type eq 3 ]
A20: Variable Set [
Name: %call_type
To: miss
Structure Output (JSON, etc): On ]
A21: End If
A22: Variable Set [
Name: %qs_note
To: #call(%call_duration) +type[%call_type] @num[%call_number] @name[%caller_name] +mode[phone]
Structure Output (JSON, etc): On ]
A23: Perform Task [
Name: Commons: POST Note & Location
Priority: %priority
Local Variable Passthrough: On
Limit Passthrough To: %qs_note, %qs_ts
Structure Output (JSON, etc): On
Continue Task After Error:On ]
A24: Variable Set [
Name: %LAST_CALLTS
To: %qs_ts
Structure Output (JSON, etc): On ]
A25: End If
Logging WhatsApp Calls
You can’t read whatsapp calls from some data provider like normal phone calls. WhatsApp also doesn’t support exporting the call logs. These calls are also not available in normal phone call logs. The only method was to read WhatsApp notification logs to get the details. Here are the steps:
Every time WhatsApp gives a notification, run the next set of steps.
If the notification was of a (audio/video) call, then get the data out in the relevant variables.
Push to an an endpoint that saves this data in a table.
Caveats:
WhatsApp generates separate calls related notifications:
incoming audio/video call
missed audio/call call (after an incoming call is missed)
If multiple calls have piled up then a separate notifation of (2+ missed calls from …)
An outgoing calls just says: “calling…” –> so, no audio/video label.
Since this is just a call notification (incoming, outgoing), there is no call duration available
Profile: Log WhatsApp Calls
Event: Notification [ Owner Application:WhatsApp Title:* Text:* Subtext:* Messages:* Other Text:* Cat:* New Only:On ]
Enter Task: WhatsApp Call Logs
A3: If [ %evtprm7 eq call ]
A4: Multiple Variables Set [
Names: %qs_ts, %call_geocoded_location, %call_countryiso, %call_type_str, %call_number, %caller_name, %call_duration, %call_type,%call_mode
Variable Names Splitter: ,
Values: %TIMEMS,,,%evtprm3,null,%evtprm2,-1,null,any
Values Splitter: ,
Structure Output (JSON, etc): On ]
A5: If [ %call_type_str ~R .*Calling.*]
A6: Variable Set [
Name: %call_type
To: out
Structure Output (JSON, etc): On ]
A7: Else
If [ %call_type_str ~R .*Incoming.*]
A8: Variable Set [
Name: %call_type
To: in
Structure Output (JSON, etc): On ]
A9: Else
If [ %call_type_str ~R .*Missed.*]
A10: Variable Set [
Name: %call_type
To: miss
Structure Output (JSON, etc): On ]
A11: End If
A12: If [ %call_type_str ~R .*voice.*]
A13: Variable Set [
Name: %call_mode
To: voice
Structure Output (JSON, etc): On ]
A14: Else
If [ %call_type_str ~R .*video.*]
A15: Variable Set [
Name: %call_mode
To: video
Structure Output (JSON, etc): On ]
A16: End If
A17: Variable Set [
Name: %qs_note
To: #call(%call_duration) +type[%call_type] @num[%call_number] @name[%caller_name] +mode[whatsapp-%call_mode]
Structure Output (JSON, etc): On ]
A18: Flash [
Text: %qs_note
Continue Task Immediately: On
Dismiss On Click: On ]
A19: Perform Task [
Name: Commons: POST Note & Location
Priority: %priority
Local Variable Passthrough: On
Limit Passthrough To: %qs_note, %qs_ts
Structure Output (JSON, etc): On
Continue Task After Error:On ]
A20: Write File [
File: Download/wa_calls.txt
Text: %qs_ts, %call_geocoded_location, %call_countryiso, %call_type_str, %call_number, %caller_name, %call_duration, %call_type,%call_mode
%qs_note
Append: On
Add Newline: On ]
A21: End If
Bye.
]]>Shivam Rana[Mini] Life Logging2025-09-27T00:00:00+00:002025-09-27T00:00:00+00:00https://trigonaminima.github.io/2025/09/life-loggingI am building a comprehensive set of tools to do life logging. General idea is:
Push everything to a sink; and
Visualise the data in this sink.
Objective is to do weekly reviews and take interventions if things are not BAU. Long term vision is to eventually have enough signals to give me a comprehensive understanding of myself (physical, mental, social, financial, etc).
2014: Gamification of Life – too much information to manage, eventually started feeling like a chore.
Bye.
]]>Shivam RanaConsolidated Recommendation Systems2025-02-13T00:00:00+00:002025-02-13T00:00:00+00:00https://trigonaminima.github.io/2025/02/consolidated-recsysThis post is a quick summary of Lessons Learnt From Consolidating ML Models in a Large Scale Recommendation System. I have also added a few questions I got while reading it. I end the post with what we do at work to deal with this.
Summary
Recommendation System: candidate gen + ranking.
A typical ranking model pipeline:
Label prep
Feature prep
Model training
Model evaluation
Model deployment (with inference contract)
Each recommendation use case (e.g.: discover page, notifications, related items, category exploration, search) will have a version of the above pipeline.
As use cases increase, the team will need to maintain multiple such pipelines. It is time-consuming to maintain multiple pipelines and increases points of failure.
Figure 1: Figure from the Netflix blog linked at the start.
Since the pipelines have the same component, we can consolidate them.
Consolidated pipeline:
Label prep for each use case separately
Stratified union of all the prepared labels
Feature prep (separate categorical feature representing the use case)
Model training
Model evaluation
Model deployment (with inference contract)
Figure 2: Figure from the Netflix blog linked at the start.
Label prep for each use case separately
Each use case will have different ways of generating the labels.
Use case context details are added as separate features.
Search context: search query, region
Similar items context: source item
When the use case is search, context features specific to the similar item use case will be filled with default values.
Union of all the prepared labels
Final labelled set: a% samples from use case-1 labels + b% samples from use case-2 labels + … + z% samples from use case-n labels
The proportions [a, b, …, z] come from stratification
Q: How is this stratification done? Platform traffic across different use cases?
Q: What are the results when these proportions are business-driven? Eg: contribution to revenue.
Feature prep
All use case specific features added to the data.
If a feature is only used for use case 1 then it will contain default value for all the other use cases.
Add a new categorical feature task_type to the features to inform the model about the target reco task.
Model training happens as usual: feature vector and labels. Architecture remains the same. Optimisation remains the same.
Model evaluation
Check the appropriate eval metrics to check the model.
Q: How do we judge if the model performed well for all the use cases?
Q: Will it require a separate evaluation set for each use case?
Q: Can there be a 2nd order Simpson’s paradox here: the consolidated model performs well, but when tried for individual use cases, its performance is low? My hunch: no.
Model deployment (with inference contract)
Deploy the same model in the respective environment made for each use case. That env will have all the specific network-related knobs: batch size, throughput, latency, caching policy, parallelism, etc.
Generic API contract to support the heterogenous context (search query for search, source item for related items use case.)
Caveats
The consolidated use cases should be related (eg: ranking for movies in the search and discover page)
One definition of related can be: ranking the same entities.
Updates (new features, architecture, etc) for one use case can be applied to other use cases.
If consolidated tasks are related, then new features don’t cause regression in practice.
Can be extended to any related use case from offline and online POV.
Cross-learning: the model potentially gains more (hidden) learning from the other tasks. Eg: having search data gives more data to the model learning for related-items task.
Q: Is this happening? How can we verify this? One way: Train an independent model on the use-case specific data and compare its performance with the consolidated model’s performance on the same task.
I was confused about what to call this learning paradigm. Wikipedia says that it is multi-task learning.
Practice at my work
The models are not merged across different tasks like relevance and search.
Within relevance ranking tasks (discover, similar items, category exploration), have a common base ranker model.
On top of that, we have different heuristics to make it better for that particular section.
Advantages:
There is only one main model for all related tasks.
Keeps the heuristics logic simple and, thus, easy to maintain.
Challenges
Heuristics are crude/manual/semi-automated → we may be leaving some gains on the table. There are bandit-based approaches to automating it, though.
It loses out on cross-learning opportunities.
]]>Shivam RanaDocument Your Progress at Work2025-01-13T00:00:00+00:002025-01-13T00:00:00+00:00https://trigonaminima.github.io/2025/01/document-your-progressHow can you ensure that your contributions are also recognized?
A common challenge, especially in larger organizations, is that your manager may not always be fully aware of the specifics of your work, and your manager’s manager likely has even less visibility. It isn’t due to a lack of interest but rather the sheer volume of responsibilities and information they handle. Additionally, even for you, it’s hard to remember all the details beyond the highlights. I find a proactive strategy essential for such scenarios: sending regular progress digests.
These digests are concise, structured email updates that you send periodically to both direct manager and their manager. The aim is to offer a clear snapshot of your activities, their impact, and your forthcoming plans. See it as a method to keep your supervisors well-informed, especially when you lack regular direct interactions.
That’s it. That is the idea. You can be creative and apply it however you want. However you decide to do it, you will see gains.
In the next section, I list the key points I usually consider in my snapshots.
Key Elements of an Effective Progress Digest
To ensure your digests are both informative and impactful, here’s what you can include:
Specific Task Details: Provide project specifics and relevant links to the completed/picked coding tasks. It entails a 1-sentence project description, PR links, JIRA tickets and other code artefacts.
Data Science Related: If applicable, detail the models you’ve trained and deployed. Any A/B experiments launched and test results of the ones that concluded. Also, share the project solutioning doc here.
Documentation Efforts: Highlight any documentation you’ve created or maintained. You can also merge this with other points.
Impact and Results: Clearly articulate the outcomes of your tasks and their value to the team and company.
Initiatives and Discussions: Share any new ideas you’ve put forward or discussions you’ve initiated.
Future Plans: Outline your planned next steps.
Benefits
The effort invested in creating these digests yields substantial career benefits:
Enhances Diligence: Summarizing your work makes you more conscious of your efforts.
Boosts Positive Perception: You are perceived as a proactive and accomplished individual.
Creates a Performance Record: These digests serve as valuable documentation of your work, valuable during performance reviews.
Ensures Visibility: Even if managers don’t respond directly to each email, they will read them, which ensures they are aware of your work and its progress.
Effective at Any Stage: While this practice is advantageous when starting a new job (or joining a new team), I have found it beneficial at any stage.
Conclusion
Actively managing your visibility is key to long-term career growth. Sending out regular progress digests ensures that your work is recognized. You also establish a record of your accomplishments and demonstrate your value. This practice requires regular work but has good returns.
PS: I learned this trick on a tech podcast many years ago. If anyone knows which podcast or episode, please share it with me, and I will link it here.
\(z^*\) is the critical value corresponding to the desired confidence level
\(\sigma\) is the population standard deviation.
\(n\) is the sample size.
The quantity \(\displaystyle {\sigma }_{\bar {x}}={\frac {\sigma }{\sqrt {n}}}\) is also called the standard error of the mean.
The 95% confidence level will correspond to the 97.5th percentile of the distribution. Reason: the probability of \(\theta\) lying outside the 95% confidence level is 5%. So, 2.5% probability on both sides (if symmetric). So the range becomes 2.5% to (95+2.5)%.
We can calculate the critical value \(z^*\) as follows:
If the sample size is small (< 30) or we do not know the std dev, then we use the t-statistic (Student’s t-distribution.) The t-distribution is wider and has heavier tails than the normal distribution, reflecting the increased uncertainty in small samples. Thus, it accounts for the extra variability.
If the sample size is large enough to make CLT valid, we use normal distribution (Z-distribution) –> z-score. Eg: a z-score of 1.96 for a 95% confidence level.
As the sample size increases, both methods converge.
The narrower the width, the higher the confidence.
Factors that impact the width of CI are sample size, variance/standard deviation, and confidence level.
Sample size high –> narrow CI
High variance/standard dev –> wider CI
Higher confidence level –> wider CI (more data will lie under a higher confidence level)
Coverage
Coverage (probability): the probability that a confidence interval will include the true value (eg: population mean.)
The proportion of CIs (at a particular confidence level) that contain the true value (eg: population mean.)
95% CI coverage: For example, if you calculate a 95% confidence interval for a population mean, you are saying that if you were to take many samples and calculate a confidence interval from each one, approximately 95% of those intervals would contain the true population mean.
Probability matching: if coverage probability is the same as nominal coverage probability.
defconfidence_interval_t(sample,confidence=0.95):"""
Calculate the confidence interval for the mean of a sample using the t-distribution.
This function is appropriate when the population standard deviation is unknown and
the sample size is small (n < 30), although it works for any sample size.
Parameters:
sample (numpy.ndarray): The sample data as a NumPy array.
confidence (float): The desired confidence level (default
is 0.95 for a 95% confidence interval).
Returns:
tuple: Lower and upper bounds of the confidence interval.
"""# Ensure the sample is a NumPy array
sample=np.array(sample)sample_mean=sample.mean()# Use Bessel's correction (ddof=1) for sample standard deviation
sample_std=sample.std(ddof=1)sample_size=len(sample)standard_error=sample_std/np.sqrt(sample_size)# Determine the critical value for the specified confidence level
critical_value=st.t.ppf((1+confidence)/2,df=sample_size-1)margin_of_error=critical_value*standard_errorlower_bound=sample_mean-margin_of_errorupper_bound=sample_mean+margin_of_errorreturnlower_bound,upper_bound
We use stats.t.ppf to get the critical value using the t-distribution. We can replace that with stats.norm.ppf for the z-score.
Confidence interval using standard normal distribution
defconfidence_interval_norm(sample,confidence=0.95):"""
Calculate the confidence interval for the mean of a sample using the normal
distribution (Z-distribution).
This function is appropriate when the population standard deviation is
known, or when the sample size is large (n >= 30), allowing the
Central Limit Theorem to approximate the sample mean's distribution as normal.
Parameters:
sample (numpy.ndarray): The sample data as a NumPy array.
confidence (float): The desired confidence level (default
is 0.95 for a 95% confidence interval).
Returns:
tuple: Lower and upper bounds of the confidence interval.
"""# Ensure the sample is a NumPy array
sample=np.array(sample)sample_mean=sample.mean()# Use Bessel's correction (ddof=1) for sample standard deviation
sample_std=sample.std(ddof=1)sample_size=len(sample)standard_error=sample_std/np.sqrt(sample_size)# Determine the critical value for the specified confidence level
critical_value=st.norm.ppf((1+confidence)/2)margin_of_error=critical_value*standard_errorlower_bound=sample_mean-margin_of_errorupper_bound=sample_mean+margin_of_errorreturnlower_bound,upper_bound
Let’s compare the results with scipy implementations.
It is the same. In the following sections, we will use the scipy functions.
CI T-distribution vs. CI Z Distribution
We will verify if the confidence interval converges as the sample size increases in both methods. We will try both on the samples generated using the following sampling methods:
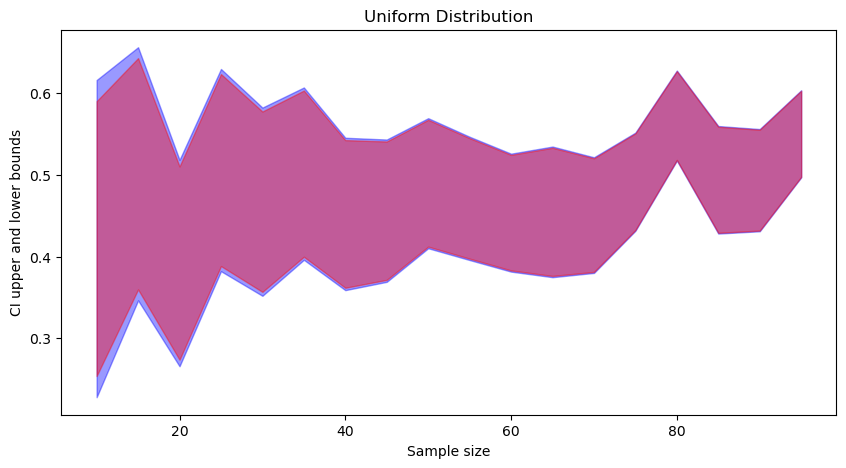
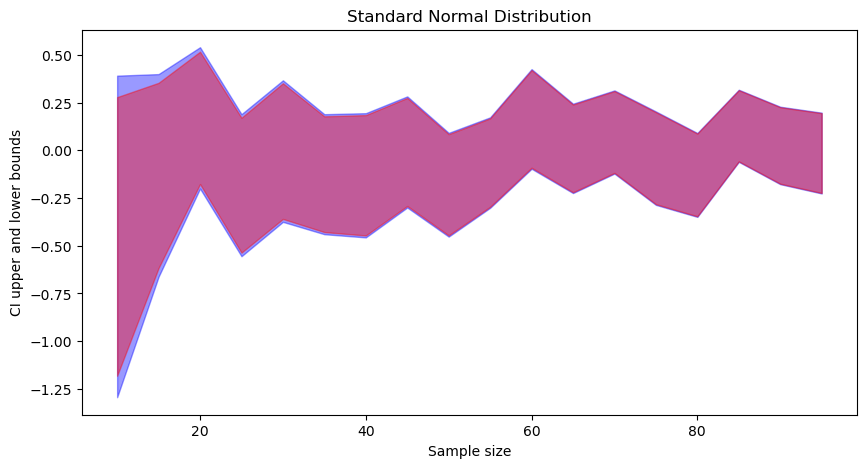
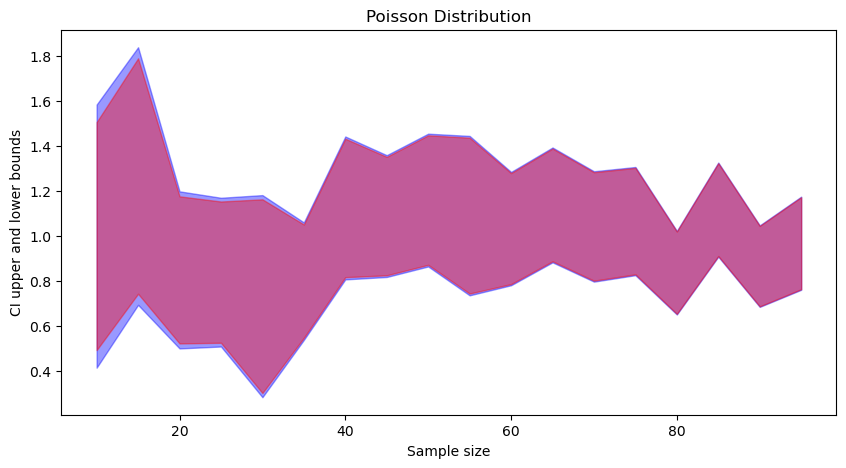
In each figure (click to zoom), the blue part corresponds to t-distribution-based CI, and the red part is to standard normal based CI. We can observe that:
t-distribution based CIs are wider than standard normal based CI.
As the sample size increases, both converge.
CI Width Simulations
Let’s visualise how the CI width changes with different factors: confidence level, sample size, and standard deviation or variance.
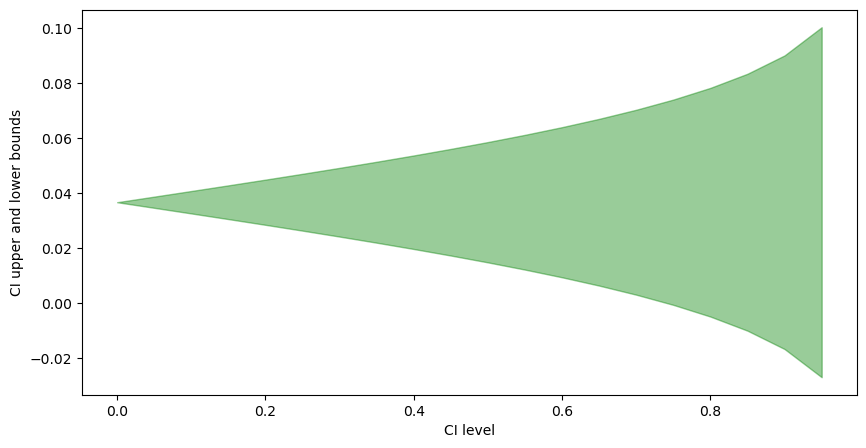
Confidence Level - \(\gamma\)
The width of CI increases as the CI level increases. Intuition: as the confidence level increases, we widen the range to get the upper and lower limits of the confidence interval.
sample=np.random.standard_normal(size=1000)sample_mean=np.mean(sample)sample_sem=st.sem(sample)cis=[]t_interval_l=[]t_interval_r=[]forciinrange(0,100,5):ci=ci*0.01t_interval=st.t.interval(confidence=ci,df=len(sample)-1,loc=sample_mean,scale=sample_sem)cis.append(ci)t_interval_l.append(t_interval[0])t_interval_r.append(t_interval[1])fig,ax=plt.subplots(figsize=(10,5))_=ax.fill_between(cis,t_interval_l,t_interval_r,color="g",alpha=0.4)_=ax.set_xlabel("CI level")_=ax.set_ylabel("CI upper and lower bounds")
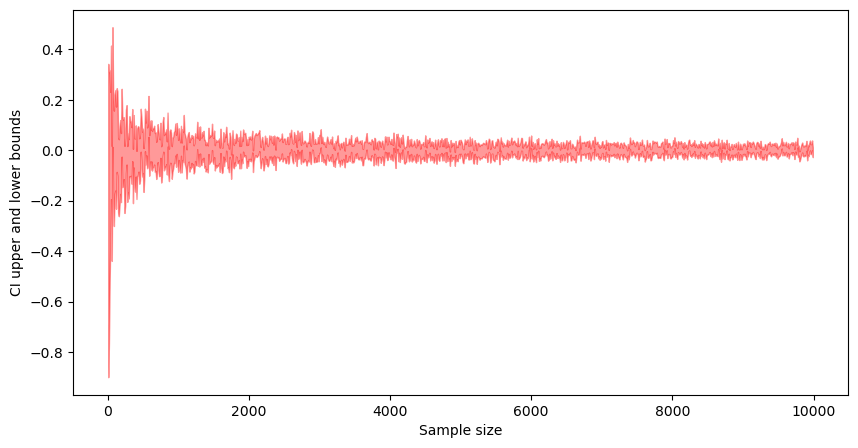
Sample Size
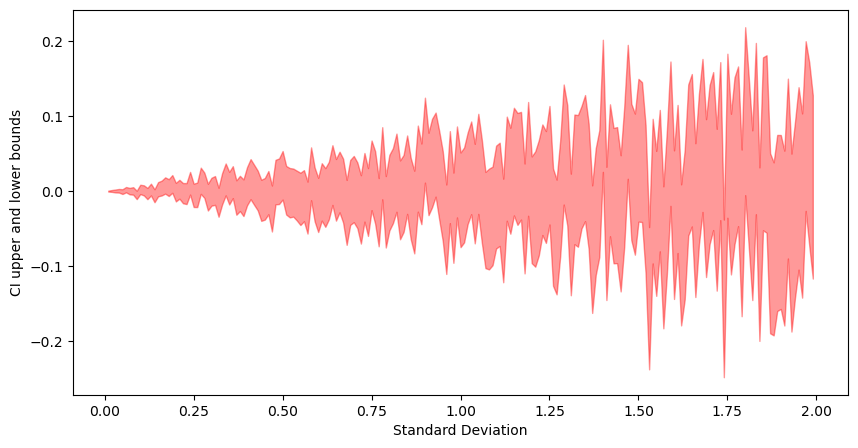
The width of CI reduces with as the sample size increases. Intuition: as sample size increases, we get more confident in our normal distribution parameter estimation, and thus, the confidence interval width reduces.
stds=[]sample_means=[]t_interval_95_l=[]t_interval_95_r=[]norm_interval_95_l=[]norm_interval_95_r=[]forstdinrange(0,200,1):std=std*0.01sample=np.random.normal(loc=0,scale=std,size=1000)t_interval_95=st.t.interval(confidence=0.95,df=len(sample)-1,loc=np.mean(sample),scale=st.sem(sample))stds.append(std)t_interval_95_l.append(t_interval_95[0])t_interval_95_r.append(t_interval_95[1])fig,ax=plt.subplots(figsize=(10,5))_=ax.fill_between(stds,t_interval_95_l,t_interval_95_r,color="r",alpha=0.4)_=ax.set_xlabel("Standard Deviation")_=ax.set_ylabel("CI upper and lower bounds")
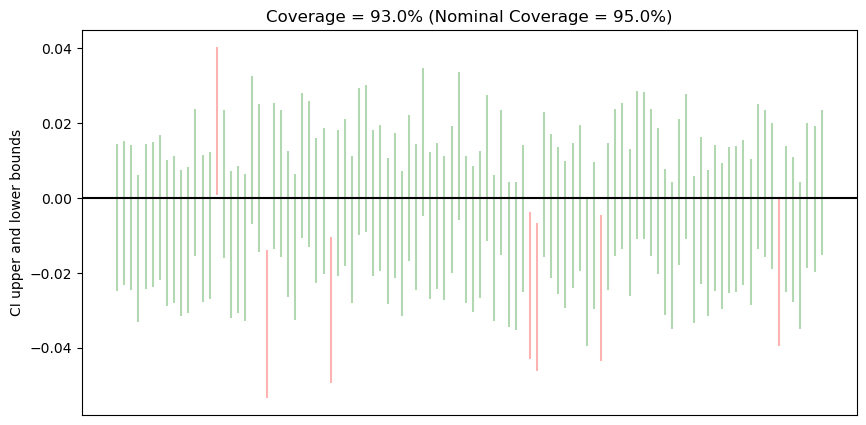
Probability Matching
Coverage probability will not always be the same as nominal coverage probability. When it matches, we get probability matching. In the below figure, out of 100 confidence intervals, 7 CIs do not contain the true mean (black.) Thus, we get a coverage of 93%, which is not the same as 95%, hence no probability matching.
A Confidence Interval is an interval over a sample that is expected to contain the distribution parameter that we are trying to estimate (eg: mean.) That means that all CIs will not contain the mean. The sample and population mean could have the following properties:
It does not contain the mean
It contains the mean somewhere in the middle
It contains the mean but as an outlier
Since the confidence interval is built from this sample using normal distribution the confidence interval may not contain the mean in the 1st or the 3rd scenario. That is why we take the confidence level as 95% or more to handle the 3rd scenario (demonstrated in the simulation section).
Since narrow-width confidence intervals are better (and more reliable), we should try to
take higher confidence levels (95% or more);
have a bigger sample size; and
have less variance in the data.
]]>Shivam RanaLognormal to Normal Distribution2024-01-14T00:00:00+00:002024-01-14T00:00:00+00:00https://trigonaminima.github.io/2024/01/lognormal-to-normalThe Normal and lognormal distributions are fundamental concepts in statistics. I recently used the relationship between these two distributions in a project. In this blog post, I want to share what I learned.
The normal distribution is also called the bell curve or Gaussian distribution. The bell height represents the mean position, and the bottom width of the bell represents the spread of values (standard deviation). Thus, the shape changes as we change mu (\(\mu\)) and sigma (\(\sigma\)). The \(\mu\) is the mean or average of the sample, and \(\sigma\) is the standard deviation. We denote a normal distribution as:
\[{\mathcal {N}}(\mu ,\sigma ^{2})\]
Find more details about the normal distribution on Wikipedia. Here are two ways of defining a normal distribution in Python.
We get a lognormal distribution when we apply exponentiation to the normal distribution. The result is a lopsided curve. It means that there is a longer tail on the right side, where larger values occur. We denote the lognormal distribution as follows:
Find more details about the lognormal distribution on Wikipedia. We define a lognormal distribution in Python as follows. The Python stdlib does not have a lognormal implementation.
Note: the scipy.stats.lognorm takes mu and sigma of the underlying normal distribution from which we derive the lognormal distribution. While providing the scale parameter, we take the exponentiation of the mean of the normal distribution. I found the documentation inadequate in explaining the parameters. This SO question has answers that discuss the meaning of the parameters.
Here is how both the distributions look for the same mu (\(\mu\)) and sigma (\(\sigma\)).
importnumpyasnpimportscipy.statsasstatsimportmatplotlib.pyplotasplt# all distributions
mu,sigma=5,.5norm_d1=NormalDist(mu,sigma)lognorm_d1=stats.lognorm(s=sigma,scale=np.exp(mu))lognorm_d1.mu,lognorm_d1.sigma=mu,sigmamu,sigma=5,1norm_d2=NormalDist(mu,sigma)lognorm_d2=stats.lognorm(s=sigma,scale=np.exp(mu))lognorm_d2.mu,lognorm_d2.sigma=mu,sigmamu,sigma=4,0.3norm_d3=NormalDist(mu,sigma)lognorm_d3=stats.lognorm(s=sigma,scale=np.exp(mu))lognorm_d3.mu,lognorm_d3.sigma=mu,sigma# norm y
x=np.linspace(0,10,500)norm_y1=np.array([norm_d1.pdf(i)foriinx])norm_y2=np.array([norm_d2.pdf(i)foriinx])norm_y3=np.array([norm_d3.pdf(i)foriinx])# lognorm y
x=np.linspace(0,800,500)lognorm_y1=np.array([lognorm_d1.pdf(i)foriinx])lognorm_y2=np.array([lognorm_d2.pdf(i)foriinx])lognorm_y3=np.array([lognorm_d3.pdf(i)foriinx])# Set the figsize
fig1,ax1=plt.subplots(figsize=(6,4))ax1.plot(x,norm_y1,label=f"mu = {norm_d1.mean}; sigma = {norm_d1.stdev}")ax1.plot(x,norm_y2,label=f"mu = {norm_d2.mean}; sigma = {norm_d2.stdev}")ax1.plot(x,norm_y3,label=f"mu = {norm_d3.mean}; sigma = {norm_d3.stdev}")ax1.legend()fig2,ax2=plt.subplots(figsize=(6,4))ax2.plot(x,lognorm_y1,label=f"mu = {lognorm_d1.mu}; sigma = {lognorm_d1.sigma}")ax2.plot(x,lognorm_y2,label=f"mu = {lognorm_d2.mu}; sigma = {lognorm_d2.sigma}")ax2.plot(x,lognorm_y3,label=f"mu = {lognorm_d3.mu}; sigma = {lognorm_d3.sigma}")ax2.legend()plt.show()fig1.savefig('norm_dist.svg',format='svg',dpi=1200,bbox_inches='tight')fig2.savefig('lognorm_dist.svg',format='svg',dpi=1200,bbox_inches='tight')
For normal distribution: Instead of using the NormalDist.pdf() we can also use numpy.random.Generator.normal to get a normal distribution sample and plot a histogram. Similarly, for lognormal distribution, instead of stats.lognorm.pdf(), we can use numpy.random.Generator.lognormal.
Normal and lognormal distributions with different mu and sigma.
Lognormal to Normal
As mentioned in the previous section, normal distribution is just a log of the lognormal distribution. So, if \({\displaystyle \ X\sim \operatorname {Lognormal} \left(\mu _{x},\sigma _{x}^{2} \right)}\), then \({\ \displaystyle \ln(X)\sim {\mathcal {N}}(\mu ,\sigma ^{2})}\).
Let us understand this by code.
1
2
3
4
5
6
7
8
9
importnumpyasnprng=np.random.default_rng()mu,sigma=5,.5lognorm_samples=rng.lognormal(mu,sigma,10000)# take the log of lognorm samples to derive the normal dist.
norm_samples=np.log(lognorm_samples)print(norm_samples.mean(),norm_samples.std())
5.005339216906491 0.4934326302969564
The parameters (mean and std) of the derived normal distribution (line 7) are the same as the original parameters we provided to the lognormal dist (line 5).
# log normal dist
fig1,ax1=plt.subplots(figsize=(5,3))ax1.hist(lognorm_samples,bins=50,alpha=0.7,density=True,color="orange")x1=np.linspace(0,800,500)lognorm_d=stats.lognorm(s=sigma,scale=np.exp(mu))lognorm_y=np.array([lognorm_d.pdf(i)foriinx1])ax1.plot(x1,lognorm_y,label=f"mu = {mu}; sigma = {sigma}")ax1.legend()# normal dist
fig2,ax2=plt.subplots(figsize=(5,3))ax2.hist(norm_samples,bins=50,alpha=0.7,density=True,color="orange")x2=np.linspace(0,7,500)norm_d=stats.norm(mu,sigma)norm_y=np.array([norm_d.pdf(i)foriinx2])ax2.plot(x2,norm_y,label=f"mu = {mu}; sigma = {sigma}")ax2.legend()plt.show()fig1.savefig('lognorm_dist2.svg',format='svg',dpi=1200,bbox_inches='tight')fig2.savefig('norm_dist2.svg',format='svg',dpi=1200,bbox_inches='tight')
Lognormal to Normal conversion.
Conclusion: to convert from a lognormal to normal, take the logarithm of the lognormal sample.
Normal to Lognormal
If the logarithm of a lognormal distribution is normally distributed, then the reverse will also be true. That is, the exponential of a normal distribution will give us a lognormal distribution. In notation, if \({\displaystyle Y\sim {\mathcal {N}}(\mu ,\sigma ^{2})}\), then \({\ \displaystyle \exp(Y)\sim \operatorname {Lognormal} \left(\mu _{x},\sigma _{x}^{2} \right)\ }\).
Let’s again understand this through code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
importnumpyasnpimportscipy.statsasstatsrng=np.random.default_rng()mu,sigma=5,.5norm_samples=rng.normal(mu,sigma,10000)# take the exp of norm samples to derive the lognormal dist.
lognorm_samples=np.exp(norm_samples)# fit a lognorm distribution to get the mean and std dev
shape,loc,scale=stats.lognorm.fit(lognorm_samples)mean,stddev=np.log(scale),shapeprint(mean,stddev)
4.984256782660331 0.5067622675605842
The parameters (mean and std) of the derived lognormal distribution (line 10) are the same as the original parameters we provided to the normal dist (line 6). Note that we used the [scipy.stats.lognorm.fit] method to fit the lognorm distribution on the data. It gives us the following three parameters: loc, shape and scale. The shape is same as standard deviation. To get the mean, we have to take the logarithm of the scale. We did not have to do this when we converted the lognormal to a normal distribution (previous section) because we can directly get the params (mean and std). Read this SO answer for more details.
Conclusion: to convert from a normal to lognormal, take exp of the normal sample.
Conclusion
We started with the Normal and Lognormal distributions and with their definition in Python. We converted each of the distributions into the other. It took me some effort to figure out how to do the conversion. With this post, I tried to demystify the confusion.
If you are interested in how other distributions look, your search is over. This SO answer has visualisations of all the distributions available in scipy.stats.
Update: 18th Jan: Someone asked me the following question on reddit.
For what purpose are you converting between normal and lognormal? The two functions share the same parameters but thats about it. ln(data) is a non-destructive transformation but the process can obscure patterns just as often as it reveals them. Certain advanced statistical tests that require a normal distribution cannot necessarily have the results applied to the lognormal data.
This stranger is correct that patterns are obscured, or rather, some other patterns come up after log transformation. Although, in my case, it did not matter.
I wanted to match the customers with the items that are within the customer spending range. The formulation was that if I have customer and outlet distributions, then I can match these distributions or get the overlap to get the match percentage. This match percentage will then be used on top of relevance scores.
Looking at the customer’s spend history, I saw that the distribution was lognormally distributed. A similar trend was observed in the restaurant’s order history. Since, computing the overlap in the production env was easier with the normal distributions, I was okay with the conversion. I will cover this in more detail in a future post.










{kind=link}